




CNNで軽量音声認識モデルを作ってTensorFlow.jsで動かしてみた
こんにちは。エンジニアの八尾です。
TensorFlow.js を使って、任意のキーワードを含む指示コマンド(短時間音声)をブラウザ上で分類できるか検証しました。今回はキーワードを「アシアル(asial)」にします。
音声データを元にしたCNN(畳み込みニューラルネットワーク)を使った約 100 KB の軽量音声認識モデルの作成手順と、Webアプリでの推論実装(マイク入力→MFCC→予測)までをまとめています。
ソースコード一式はこちらのリポジトリで公開しています。
https://github.com/ytatsuno/202601_voice_recognition
1. TensorFlow.js とは
TensorFlow.js は、ブラウザや Node.js 上で機械学習モデルの学習・推論ができる JavaScript 向けフレームワークです。
内部では Tensor(テンソル、テンサー) という多次元配列データ構造を使い、ニューラルネットワークとデータのやり取りを行います。
そのため、Webサイトや IoT デバイスなどでも、モデル推論を比較的手軽に組み込めます。
2. 「アシアル」を認識するカスタム音声モデルを作成
今回作成したモデルは、以下のクラスを分類します。
- 指示コマンド:`up, down, left, right, go, stop`
- 追加コマンド:`asial`
- 特殊クラス:`unknown`, `background_noise`指示コマンド(短時間音声)のデータは、TensorFlow が提供している Speech Commands データセットを利用しました。
Speech Commands
2-1. 録音データを集める
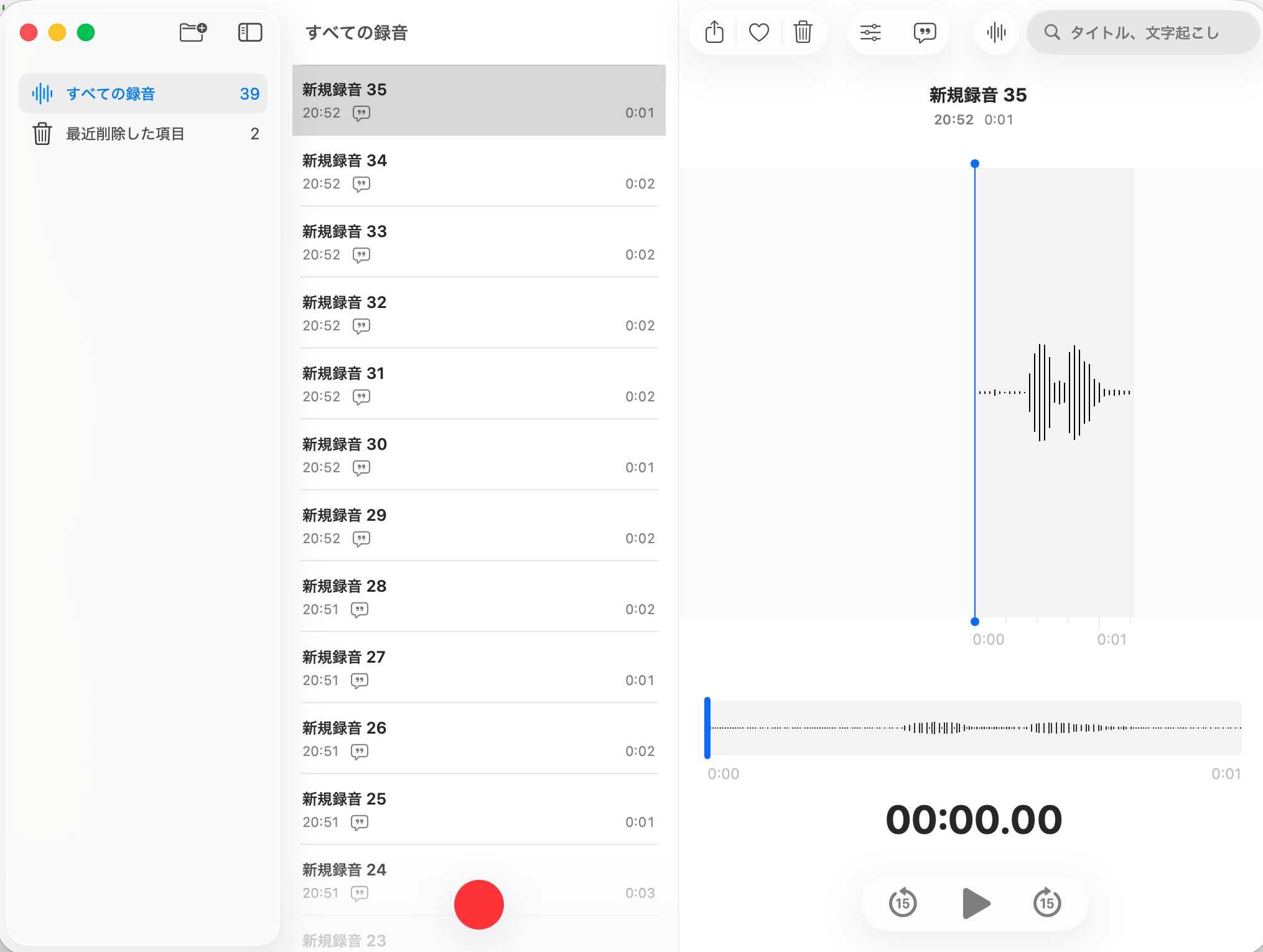
MacBook Air の「ボイスメモ」で asial の音声を収録します。
- 「ボイスメモ」を開く
- 赤い録音ボタンを��押す
- 0.5秒待ってから「アシアル」と1回発話
- 0.5秒待って停止
- タイトルを分かるように変更
- 例:
asial_yao_001(キーワード_話者名_連番)
- 例:
目安として 1人あたり 100〜300 件用意します。今回は CNN かつ軽量モデルを利用しているため、比較的多くのデータが必要です。
(今回は検証のため、1人分のみ作成しました)
2-2. 録音データを成形する
Speech Commands 系の短時間音声運用に合わせるため、ffmpeg で音声の形式・長さを揃えます。
形式:WAV
コーデック:PCM(非圧縮)
サンプルレート:16,000 Hz
チャンネル:1(mono)
ビット深度:16-bit(pcm_s16le)
長さ:1.0秒(speech-commands系の短音コマンド運用に合わせやすい)以下のようなスクリプトで、ffmpeg を利用して dataset ディレクトリ内の m4a ファイルを wav に変換しました。
# m4a => wav 変換
ffmpeg -i input.m4a -ac 1 -ar 16000 -c:a pcm_s16le input.wav
# 開始から0.5秒後から、長さ:1.0秒間の wav に変換
ffmpeg -i input.wav -ss 0.5 -t 1.0 -ac 1 -ar 16000 -c:a pcm_s16le cut.wav2-3. 音声解析モデルの作成
モデル学習は Google Colab で行いました。
使用したノートブック(ipynb)はこちらです。
ipynbのリンク
処理の流れは以下の通りです。
- Speech Commands をダウンロード
- 既存の指示コマンド(
up, down, left, right, go, stop)とunknown用データとして利用
- 既存の指示コマンド(
_background_noise_ディレクトリに含まれる長尺ノイズ音声から 1 秒のノイズ片を作り、学習時にランダムにミックス- 追加コマンド
asialの音声を Google Drive(My Drive)から読み込み - 前処理(特徴量変換)を実行
- 指示コマンドの音声WAV を 16kHz / mono / 1.0秒 / float32 に統一(重要)
- 波形(時間領域): Float32Array => Tensor1D化
- Tensor1D化した波形 => 短時間フーリエ変換(複素数)
- 波形の複素スペクトル => スペクトログラム(振幅(magnitude)を利用)へ変換
- スペクトログラム => 波形のメル尺度(音の高低の尺度) を計算
- 波形のメル尺度 => MFCC(メル周波数ケプストラム係数)のまとまりに変換
- モデル入力形状に合わせて Tensor を [T, 13] から [1, T, 13, 1] に次元拡張
- 成形したデータを用いて CNN(畳み込みニューラルネットワーク)を学習
- 学習済みモデルを TensorFlow.js 向けに変換し
model.jsonを出力
2-4. 完成した音声解析モデル
3層CNNによるシンプルな構成です。
入力 (MFCC 13次元)
↓
Conv2D (16) → MaxPool
↓
Conv2D (32) → MaxPool → Dropout
↓
Conv2D (64) → GlobalAvgPool → Dropout
↓
Dense (9クラス, softmax)
- パラメータ数: 約24,000
- ファイルサイズ: 約100KB3. (ブラウザ側)音声推論処理の実装
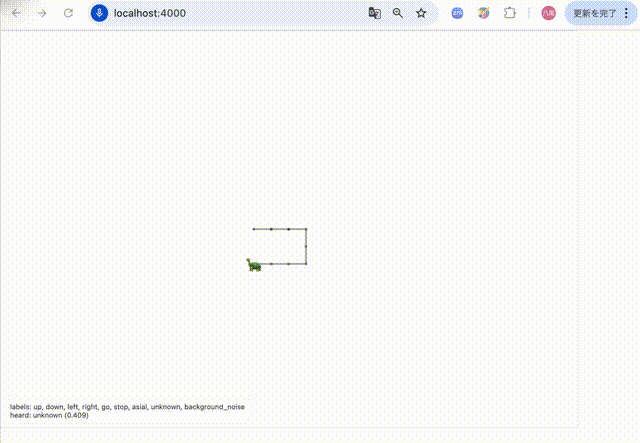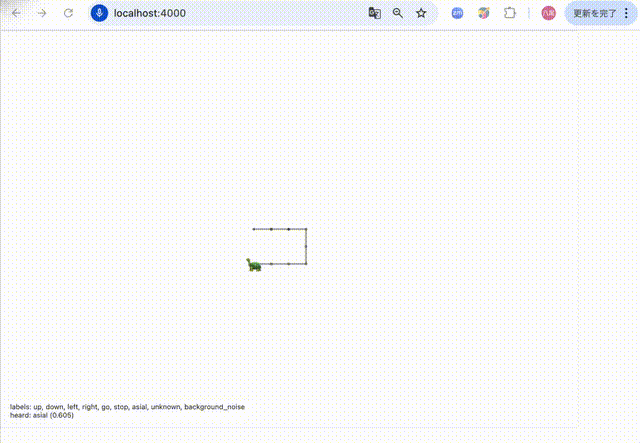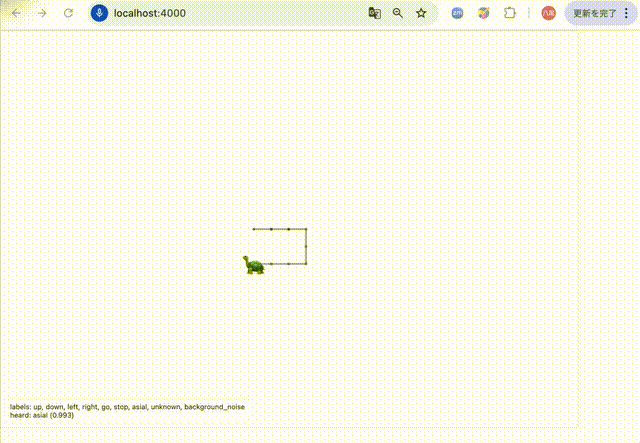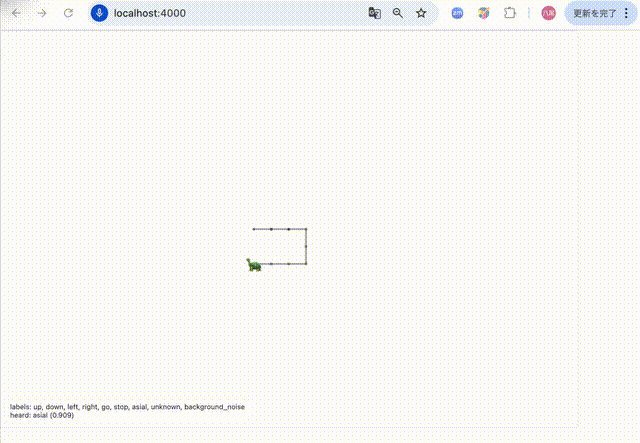
こちらの音声認識のモデルを利用して以下のWebアプリを作成しました。
- 絵文字「:turtle:」を画面中央に描画
-「up」、「down」、「left」、「right」が音声認識で聞こえたら�、「:turtle:」の向きを変更
-「go」 を音声認識で聞こえたら、「:turtle:」の位置を変更(向いている方向へ + 1 )
-「asial」が聞こえたら「:turtle:」の大きさを40pxに変更し元の大きさに戻す変更
-「stop」 を音声認識で聞こえたら、「アプリ終了」を表示して voiceRecognition も止める動作は以下のような動きとなりました。「asial」という言葉に反応して亀のサイズが変化しているのが分かります。
推論までの流れは以下です。
AudioContextから音声データをFloat32Array(1次元配列)として取得- 取得した波形を、モデル入力形式(MFCC)へ変換(方式は学習時の前処理と同様)
- 1秒分のMFCCのまとまりについて、model.predict を実行
実装は以下の通りとなります。
www/js/asialVoiceRecognition.js
// ------------- グローバル変数 -------------
let model, labels;
// ------------- 音声の基本パラメータ -------------
// このサンプルは「16kHz / 1秒」の固定長クリップを前提にしています。
const SR = 16000; // サンプリング周波数 (Hz)
const CLIP_SECONDS = 1.0; // 1回の推論に使う長さ(秒)
const CLIP_SAMPLES = SR * CLIP_SECONDS; // 1秒ぶんのサンプル数(=16000)
// ------------- 特徴量(STFT / Mel / MFCC)のパラメータ -------------
// ★ここは学習時と一致している必要があります(窓長/ステップ/FFT長が違うと次元や分布がズレる)
const frameLength = 640; // 40ms (= 16000Hz * 0.04s)
const frameStep = 320; // 20ms (= 16000Hz * 0.02s)
const fftLength = 1024;
// Melフィルタバンクの数と、最終的に使うMFCC係数数
const numMelBins = 40;
const numMfcc = 13;
// Melフィルタの周波数レンジ
const lowerEdgeHz = 20.0;
const upperEdgeHz = SR / 2; // ナイキスト周波数(= 8000Hz)
// STFTの出力(rfft)の周波数bin数
// rfftのユニークbin数 = fftLength/2 + 1
const numSpectrogramBins = fftLength / 2 + 1;
// ------------- キャッシュ(毎フレーム作らない) -------------
// Mel重み行列とDCT行列は毎回作ると重いので、初回だけ作って保持します。
let melW = null; // shape: [numSpectrogramBins, numMelBins]
let dctM = null; // shape: [numMelBins, numMfcc]
// ------------- Hz <-> Mel 変換 -------------
function hzToMel(hz) {
return 2595 * Math.log10(1 + hz / 700);
}
function melToHz(mel) {
return 700 * (Math.pow(10, mel / 2595) - 1);
}
// ------------- Melフィルタバンク重み行列を生成 -------------
// 目的:
// |spectrogram| (T x numSpectrogramBins) に掛けることで
// mel (T x numMelBins) を得るための重み行列を作る
//
// 返り値:
// shape [numSpectrogramBins, numMelBins]
// ※あとで spectrogram.matMul(melW) する想定
function buildMelWeightMatrix(numMelBins, numSpectrogramBins, sampleRate, lowerEdgeHz, upperEdgeHz) {
// numSpectrogramBins = fftLength/2 + 1 なので、fftLength は (numSpectrogramBins - 1) * 2 で戻せる
const fftLen = (numSpectrogramBins - 1) * 2;
// 周波数レンジをMelスケールに変換
const lowerMel = hzToMel(lowerEdgeHz);
const upperMel = hzToMel(upperEdgeHz);
// Mel上で等間隔な「三角フィルタ」の中心点(+両端)を作る
// 三角フィルタは numMelBins 個必要なので、境界も含めて numMelBins+2 点
const melPoints = new Array(numMelBins + 2);
for (let i = 0; i < melPoints.length; i++) {
melPoints[i] = lowerMel + (upperMel - lowerMel) * (i / (numMelBins + 1));
}
// Mel点をHzに戻す
const hzPoints = melPoints.map(melToHz);
// Hz -> FFT bin index へ変換
// (fftLen+1) を掛けているのは実装上の一般的な換算(学習実装に合わせるのが大事)
const bin = hzPoints.map(hz => Math.floor((fftLen + 1) * hz / sampleRate));
// 重み行列本体(2Dを1Dに詰めて最後にtensor2d化)
// shape: [numSpectrogramBins, numMelBins]
const data = new Float32Array(numSpectrogramBins * numMelBins);
// m番目の三角フィルタ(m=1..numMelBins)を作る
for (let m = 1; m <= numMelBins; m++) {
// 三角の左端/中心/右端(FFT bin)
const f0 = bin[m - 1];
const f1 = bin[m];
const f2 = bin[m + 1];
// 上り部分:f0 -> f1 で 0 -> 1
for (let k = f0; k < f1; k++) {
if (k >= 0 && k < numSpectrogramBins && f1 !== f0) {
const w = (k - f0) / (f1 - f0);
data[k * numMelBins + (m - 1)] = w;
}
}
// 下り部分:f1 -> f2 で 1 -> 0
for (let k = f1; k < f2; k++) {
if (k >= 0 && k < numSpectrogramBins && f2 !== f1) {
const w = (f2 - k) / (f2 - f1);
data[k * numMelBins + (m - 1)] = Math.max(0, w);
}
}
}
return tf.tensor2d(data, [numSpectrogramBins, numMelBins], 'float32');
}
// ------------- DCT-II(直交正規化)行列を生成 -------------
// 目的:
// log-mel (T x numMelBins) に掛けて MFCC (T x numMfcc) を得る
//
// 返り値:
// shape [numMelBins, numMfcc]
function buildDctMatrix(numMelBins, numMfcc) {
const data = new Float32Array(numMelBins * numMfcc);
// k=0 とそれ以外でスケールが違う(直交正規化)
const scale0 = 1 / Math.sqrt(numMelBins);
const scale = Math.sqrt(2 / numMelBins);
// n: mel bin index, k: mfcc index
for (let k = 0; k < numMfcc; k++) {
for (let n = 0; n < numMelBins; n++) {
const basis = Math.cos(Math.PI / numMelBins * (n + 0.5) * k);
data[n * numMfcc + k] = (k === 0 ? scale0 : scale) * basis;
}
}
return tf.tensor2d(data, [numMelBins, numMfcc], 'float32');
}
// ------------- 特徴量変換用行列の初期化(キャッシュ) -------------
function ensureFeatureMatrices() {
if (!melW) melW = buildMelWeightMatrix(numMelBins, numSpectrogramBins, SR, lowerEdgeHz, upperEdgeHz);
if (!dctM) dctM = buildDctMatrix(numMelBins, numMfcc);
}
// -----------------------------------------------------------------------------
// 音声クリップ(1秒, 16kHz想定)をモデル入力用のMFCCテンソルに変換する
//
// 入力:
// audio1d: Float32Array などの1次元配列
// 長さは CLIP_SAMPLES (= SR * CLIP_SECONDS) を想定
//
// 出力:
// tf.Tensor, shape: [1, T, numMfcc(=13), 1]
// - 先頭の 1 : バッチ次元(1クリップ分)
// - T : 時間フレーム数(frameLength / frameStep / 入力長で決まる)
// - 13 : MFCC 次元(各フレームの特徴量数)
// - 最後の 1 : チャンネル次元(CNN等「画像扱い」の入力形状に合わせるため)
//
// 処理の流れ:
// wav(波形) → STFT(複素スペクトル) → |.|(振幅スペクトログラム)
// → Melフィルタバンク → log → DCT → MFCC
//
// メモリ:
// tf.tidy() により、この関数内で生成した中間Tensorは自動的に破棄される
// (return する MFCC テンソルだけが tidy の外に残る)
// -----------------------------------------------------------------------------
function audioToMfcc(audio1d) {
// Mel重み行列(melW)とDCT行列(dctM)を未作成なら生成してキャッシュする
ensureFeatureMatrices();
return tf.tidy(() => {
// 1) 波形(時間領域): JS配列/TypedArray -> Tensor1D へ
const wav = tf.tensor1d(audio1d);
// 2) STFT: 短時間フーリエ変換(複素数)
// shape: [T, numSpectrogramBins](numSpectrogramBins = fftLength/2 + 1)
const stft = tf.signal.stft(wav, frameLength, frameStep, fftLength);
// 3) 複素スペクトル -> スペクトログラムへ
// ここでは振幅(magnitude)= abs を採用
// ※学習時が「パワー(magnitude^2)」なら square() 等に合わせる必要あり
const spectrogram = tf.abs(stft); // shape: [T, numSpectrogramBins]
// 4) Melフィルタバンク適用: 周波数bin -> Mel帯域へ集約
// (T x bins) @ (bins x mel) => (T x mel)
const mel = spectrogram.matMul(melW); // shape: [T, numMelBins]
// 5) log-Mel: 強度を対数圧縮(0回避のため微小値を加算)
const logMel = tf.log(mel.add(1e-6)); // shape: [T, numMelBins]
// 6) DCTでMFCCへ: (T x mel) @ (mel x mfcc) => (T x mfcc)
// Mel帯域の情報を少数次元(ここでは13)に圧縮し、音声識別に使いやすくする
const mfcc = logMel.matMul(dctM); // shape: [T, numMfcc]
// 7) モデル入力形状に合わせて次元追加
// [T, 13] -> [T, 13, 1] -> [1, T, 13, 1]
return mfcc.expandDims(-1).expandDims(0);
});
}
// ------------- モデルとラベルの読み込み -------------
async function loadAssets() {
// 例: ./tfjs_model_tfonly/model.json と ./tfjs_model_tfonly/labels.json がある想定
// model.json は tfjs-converter などで出力されたKeras互換のモデル
model = await tf.loadLayersModel("./tfjs_model/model.json");
// labels.json は { "labels": ["silence", "yes", ...] } のような形式を想定
labels = await (await fetch("./tfjs_model/labels.json")).json();
// ラベル一覧を画面に表示
document.querySelector("#words").textContent = labels.labels.join(", ");
}
// ------------- マイク入力をループして推論する -------------
async function startMicLoop(onaudioprocessCallback) {
// マイク許可を取り、音声ストリームを取得
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
// AudioContext を 16kHz 指定で生成�(環境により厳密に16kHzにならない場合もあります)
const audioCtx = new (window.AudioContext || window.webkitAudioContext)({ sampleRate: SR });
// MediaStream -> AudioNode
const source = audioCtx.createMediaStreamSource(stream);
// ScriptProcessorNode(レガシーAPI)
// 4096サンプル単位でコールバックが来る(16kHzなら約256msごと)
// ※本格運用なら AudioWorklet が推奨ですが、最小構成としてScriptProcessorを使用
const processor = audioCtx.createScriptProcessor(4096, 1, 1);
// ここに入力音声を溜めていく(可変長)
let buffer = new Float32Array(0);
let running = true;
// 音声が来るたびに呼ばれる
processor.onaudioprocess = async (e) => {
// モノラル1ch想定で0番を取る
const input = e.inputBuffer.getChannelData(0);
// 既存bufferの末尾に input を連結
const tmp = new Float32Array(buffer.length + input.length);
tmp.set(buffer, 0);
tmp.set(input, buffer.length);
buffer = tmp;
// 1秒分たまったら推論
// (重い場合は、推論間隔を長くする/キュー化/非同期制御などを検討)
if (buffer.length >= CLIP_SAMPLES) {
// 先頭から1秒を切り出し
const clip = buffer.slice(0, CLIP_SAMPLES);
// 次回に向けて半分(0.5秒)だけ残して捨てる = 0.5秒オーバーラップ
buffer = buffer.slice(Math.floor(CLIP_SAMPLES / 2));
// 特徴量化してモデル入力へ
const x = audioToMfcc(clip);
// 推論
// model.predict は通常 Tensor を返す(分類なら shape [1, numLabels] 等)
const y = model.predict(x);
// Tensor -> JS配列へ(GPU/wasm→CPUへ転送が発生)
const scores = await y.data();
// tidy外のTensorなので明示破棄
x.dispose();
y.dispose();
if(onaudioprocessCallback && typeof onaudioprocessCallback === 'function') {
onaudioprocessCallback(scores, labels);
}
}
};
// ノード接続
// source -> processor へ入力を流し、
// processor -> destination へ繋がないとScriptProcessorが動かない実装が多いです
source.connect(processor);
processor.connect(audioCtx.destination);
// 停止用コントローラを返す
return {
stop: async () => {
running = false;
try { processor.disconnect(); } catch {}
try { source.disconnect(); } catch {}
try {
stream.getTracks().forEach(t => t.stop());
} catch {}
try {
await audioCtx.close();
} catch {}
}
};
}index.html
<html>
<head>
<meta charset="utf-8" />
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs"></script>
<style>
html, body {
margin: 0;
padding: 0;
height: 100%;
background: #fefefe; /* ★背景 */
color: #111;
font-family: system-ui, -apple-system, "Segoe UI", Roboto, "Noto Sans JP", sans-serif;
}
/* 画面左上から 90% x 90% を使う */
#stage {
position: absolute;
left: 0;
top: 0;
width: 90vw;
height: 90vh;
border: 1px solid rgba(0,0,0,0.15);
box-sizing: border-box;
overflow: hidden;
background: #fefefe; /* ★背景(念のため) */
}
/* ★描画は canvas に寄せる */
#gameCanvas {
display: block;
width: 100%;
height: 100%;
}
#hud {
position: absolute;
left: 8px;
bottom: 8px;
font-size: 12px;
opacity: 0.9;
background: rgba(255,255,255,0.75);
color: #111;
padding: 6px 8px;
border-radius: 8px;
border: 1px solid rgba(0,0,0,0.08);
backdrop-filter: blur(4px);
}
#endOverlay {
position: absolute;
inset: 0;
display: none;
align-items: center;
justify-content: center;
font-size: 32px;
background: rgba(255,255,255,0.75);
color: #111;
}
</style>
</head>
<body>
<div id="stage">
<canvas id="gameCanvas"></canvas>
<div id="endOverlay">アプリ終了</div>
<div id="hud">
<div>labels: <span id="words">(loading...)</span></div>
<div>heard: <span id="heard">(none)</span></div>
</div>
</div>
<script src="./js/asialVoiceRecognition.js"></script>
<script>
// ---------------- DOM ----------------
const stage = document.getElementById("stage");
const canvas = document.getElementById("gameCanvas");
const ctx = canvas.getContext("2d");
const endOverlay = document.getElementById("endOverlay");
const heardEl = document.getElementById("heard");
// HUD表示は既存のまま利用
const wordsEl = document.getElementById("words");
// ---------------- 状態 ----------------
const BASE_SIZE_PX = 28;
const ASIAL_SIZE_PX = 40;
// 「+1」の単位(グリッド1マス分)
const STEP_PX = 30;
// 方向(あなたの手元で動いている rot を踏襲)
// ※rot は「絵文字の向き」を canvas で回転して描くために使う
const DIRECTIONS = {
up: { dx: 0, dy: -1, rot: 90 },
left: { dx: -1, dy: 0, rot: 0 },
down: { dx: 0, dy: 1, rot: -90 },
right: { dx: 1, dy: 0, rot: 180 },
};
let dir = "left";
let gridX = 0;
let gridY = 0;
// 連打防止
const COOLDOWN_MS = 700;
let lastCmdAt = 0;
// asial パルス
let asialTimer = null;
let turtleSizePx = BASE_SIZE_PX;
// stop されたか
let ended = false;
// startMicLoop の controller
let micController = null;
// ★軌跡(通った地点を保存)
// 中央を (0,0) とする「グリッド座標」で保存して、描画時に px に変換
const trail = [{ x: 0, y: 0 }];
// ---------------- 位置変換 ----------------
function getStageSize() {
return { w: stage.clientWidth, h: stage.clientHeight };
}
function gridToPx(gx, gy) {
const { w, h } = getStageSize();
const centerX = Math.floor(w / 2);
const centerY = Math.floor(h / 2);
return {
x: centerX + gx * STEP_PX,
y: centerY + gy * STEP_PX,
};
}
// ---------------- canvas リサイズ ----------------
function resizeCanvas() {
// CSSサイズと実ピクセルを一致させる(高DPI対応)
const { w, h } = getStageSize();
const dpr = window.devicePixelRatio || 1;
canvas.width = Math.floor(w * dpr);
canvas.height = Math.floor(h * dpr);
canvas.style.width = w + "px";
canvas.style.height = h + "px";
ctx.setTransform(dpr, 0, 0, dpr, 0, 0);
draw(); // リサイズ時に再描画
}
// ---------------- 描画 ----------------
function clearBackground() {
const { w, h } = getStageSize();
ctx.clearRect(0, 0, w, h);
ctx.fillStyle = "#fefefe";
ctx.fillRect(0, 0, w, h);
}
function drawTrail() {
if (trail.length < 2) return;
ctx.save();
ctx.lineWidth = 3;
ctx.lineJoin = "round";
ctx.lineCap = "round";
ctx.strokeStyle = "rgba(20, 20, 20, 0.35)";
ctx.beginPath();
const p0 = gridToPx(trail[0].x, trail[0].y);
ctx.moveTo(p0.x, p0.y);
for (let i = 1; i < trail.length; i++) {
const p = gridToPx(trail[i].x, trail[i].y);
ctx.lineTo(p.x, p.y);
}
ctx.stroke();
ctx.restore();
// 点も少し強調(見やすく)
ctx.save();
ctx.fillStyle = "rgba(20, 20, 20, 0.35)";
for (const t of trail) {
const p = gridToPx(t.x, t.y);
ctx.beginPath();
ctx.arc(p.x, p.y, 2.5, 0, Math.PI * 2);
ctx.fill();
}
ctx.restore();
}
function drawTurtle() {
const { w, h } = getStageSize();
const margin = 20;
let p = gridToPx(gridX, gridY);
// クランプ(canvas 版でも同様)
p.x = Math.max(margin, Math.min(w - margin, p.x));
p.y = Math.max(margin, Math.min(h - margin, p.y));
ctx.save();
ctx.translate(p.x, p.y);
ctx.rotate((DIRECTIONS[dir].rot * Math.PI) / 180);
ctx.font = `${turtleSizePx}px system-ui, "Apple Color Emoji", "Segoe UI Emoji", "Noto Color Emoji"`;
ctx.textAlign = "center";
ctx.textBaseline = "middle";
ctx.fillStyle = "#111";
ctx.fillText("🐢", 0, 0);
ctx.restore();
}
function draw() {
clearBackground();
drawTrail();
drawTurtle();
}
// ---------------- 操作 ----------------
function setDirection(newDir) {
if (!DIRECTIONS[newDir]) return;
dir = newDir;
draw();
}
function goForward() {
gridX += DIRECTIONS[dir].dx;
gridY += DIRECTIONS[dir].dy;
// ★軌跡に追加(同じ点連続追加は避ける)
const last = trail[trail.length - 1];
if (!last || last.x !== gridX || last.y !== gridY) {
trail.push({ x: gridX, y: gridY });
}
draw();
}
function asialPulse() {
clearTimeout(asialTimer);
turtleSizePx = ASIAL_SIZE_PX;
draw();
asialTimer = setTimeout(() => {
turtleSizePx = BASE_SIZE_PX;
draw();
}, 350);
}
function endApp() {
if (ended) return;
ended = true;
endOverlay.style.display = "flex";
if (micController && typeof micController.stop === "function") {
micController.stop();
}
}
function shouldAcceptCommand(now) {
if (ended) return false;
if (now - lastCmdAt < COOLDOWN_MS) return false;
lastCmdAt = now;
return true;
}
// ---------------- アプリ起動 ----------------
async function app() {
// 初期描画
turtleSizePx = BASE_SIZE_PX;
resizeCanvas();
await loadAssets();
// labels を HUD へ(asialVoiceRecognition.js 側が既に書いてくれるなら不要だが、念のため)
if (wordsEl && window.labels && window.labels.labels) {
wordsEl.textContent = window.labels.labels.join(", ");
}
micController = await startMicLoop((scores, labels) => {
if (ended) return;
// 推論結果のベストを探す
let bestIdx = 0;
for (let i = 1; i < scores.length; i++) {
if (scores[i] > scores[bestIdx]) bestIdx = i;
}
const bestWord = labels.labels[bestIdx];
const bestScore = scores[bestIdx];
heardEl.textContent = `${bestWord} (${bestScore.toFixed(3)})`;
const THRESHOLD = 0.60;
if (bestScore < THRESHOLD) return;
const now = Date.now();
if (bestWord === "stop") {
endApp();
return;
}
if (!shouldAcceptCommand(now)) return;
if (bestWord === "up" || bestWord === "down" || bestWord === "left" || bestWord === "right") {
setDirection(bestWord);
return;
}
if (bestWord === "go") {
goForward();
return;
}
if (bestWord === "asial") {
asialPulse();
return;
}
});
}
window.addEventListener("resize", resizeCanvas);
app();
</script>
</body>
</html>4. 感想
- 今回は私の声だけで asial コマンドを学習したため、私以外に喋ってもらったときは精度が落ちやすいと感じました。
複数人の音声データで学習し、汎化性能を上げたいです。 - 今回のモデルは、約100KBと軽量で音声を推論できるため、推論側で同じ前処理(Float32Array → MFCC)を行えば、ブラウザ以外(アプリ/IoTデバイス等)でも同様に動かせる可能性があります。
次は別プラットフォームへの移植性も検証し�てみたいです。 - 短い単語(キーワード)を音声で認識し、Webアプリを操作できる点は、TensorFlow.js を使うことで実現できる新しいユーザビリティの可能性を感じました。
- 例えば go や left のような単語を繰り返し発話して操作する仕組みは、英語の発音練習(正しい発音の定着)にもつながりそうです。
- また、音声コマンドに会社名(例:asial)を組み込むことで、ユーザーの体験の中で自然にブランド名が触れられるため、ブランド認知を促す仕掛けとしても活用できると思いました。
参考
- How to Use Embedded Machine Learning to Do Speech Recognition on Arduino https://www.digikey.com/en/maker/projects/how-to-use-embedded-machine-learning-to-do-speech-recognition-on-arduino/1d5dd38c05d9494180d5e5b7b657804d
- Speech Commands Dataset(Google): https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.02.tar.gz





















