





TSKaigi 2025レポート
テクノロジー2025年6月30日

Cursorを使ってみた – AI時代のペアプロ環境
テクノロジー2025年6月18日
40歳、デザイナーとしてこれからを考える
UX/UI2025年5月28日
Tech勉強会レポート – 802.1X認証の紹介/PHP Conference Japan 2024 レポート
その他2025年5月8日
Next.js v15.2で使えるようになった View Transition API を試してみた
テクノロジー2025年4月21日
Passkeyで実現する次世代ログイン体験|パスワードレス認証を試してみた
テクノロジー2025年4月7日
Flutterアプリを自動テストしたい話
テクノロジー2025年3月17日
Windows PCからiOSのコンソールログを見る方法
その他2025年3月3日
AIのOS操作能力を 評価するベンチマーク「OSWorld」
テクノロジー2025年2月26日
Tech勉強会レポート – RemixとWakuの紹介/技術選定について
その他2025年2月12日
デザイナーからのテック相談 エピソード1:UIデザイナーが、要件定義・設計フェーズに関わるメリット
UX/UI2025年1月27日
アシアルのオンボーディング・OJT体験記 〜入社から実務までの流れ〜
その他2025年1月7日
Tech勉強会レポート -Selenium+AWS LambdaでWebスクレイピング実行/Next.js 15を使ってみて感じたこと-
テクノロジー2024年12月23日
Pythonを使って、RSA暗号を調べてみました
テクノロジー2024年12月2日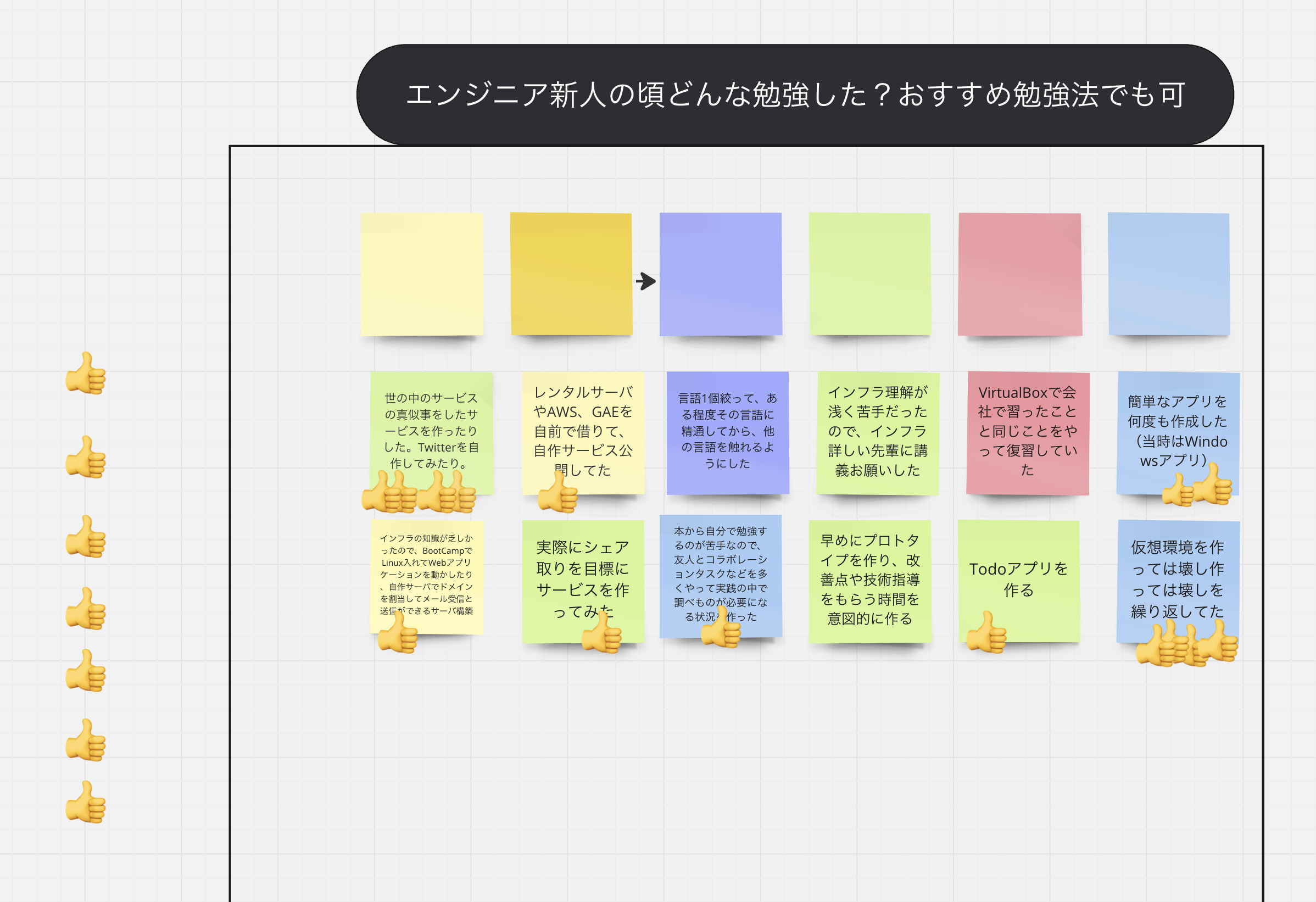
2024/10月社内Tech勉強会レポート – AWSを使ったイベント駆動サイトを開発した時の話 & Miroでブレストワークショップ –
AWS2024年11月18日
生成AIを業務で活用できたケースの紹介/アウトプット推進チームからの活動報告
その他2024年11月5日
ChromeからChatGPT Searchを使う場合のTIPS
その他2024年11月4日
コードレビュー文化のある組織づくり
その他2024年10月28日
ESP32でAirTagを自作してみた(OpenHayStack + HomeAssistant + ESPHome)
テクノロジー2024年9月30日
「Tokens Studio for Figma」を使用してデザイントークンを管理する(基本編)
UX/UI2024年9月17日
「TOPS」を計算してみよう 〜 AI対応PCの性能指標
テクノロジー2024年8月19日
2024/6月社内Tech勉強会レポート – AWS生成AI(GenU)ワークショップ体験記
その他2024年6月27日
2024/4月社内Tech勉強会レポート – Next.jsでGemini動かしてみた
その他2024年6月20日
難問データセットSWE-benchとは?AIによるプログラミング能力の新たな評価基準
テクノロジー2024年4月20日
AIに仕事をさせましょう、CrewAIと共に
その他2024年4月18日
2024/3月社内Tech勉強会レポート – オフライン/PyTorchによる株価予測モデルなど
その他2024年4月9日
サーバントリーダシップとは?
その他2024年3月27日
2024/1月社内Tech勉強会レポート – Flutter の簡単な紹介 / Vue2がEOL / Vue2 NES
その他2024年3月11日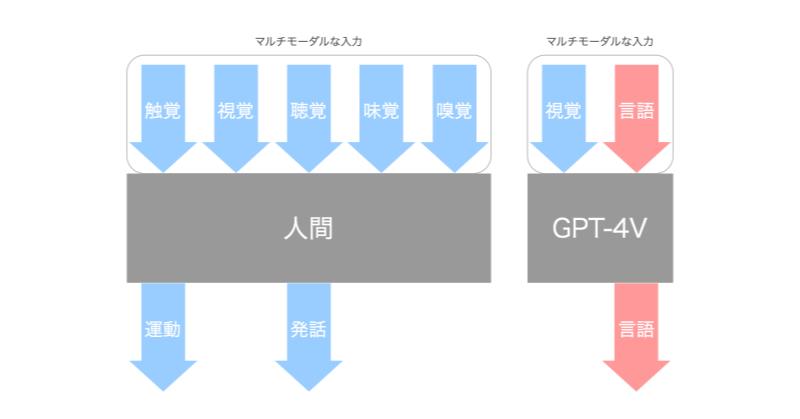
図解で分かる!モダリティとマルチモーダルAI
テクノロジー2024年3月4日
Flutter flame を試してみる
その他2024年2月1日
cordova-plugin-firebasex特有のビルドエラーについて
Monaca2024年1月9日
11月社内Tech勉強会レポート – AI / Git2.43 / git repack / Azure OpenAI Serivce
その他2023年12月25日
Monacaアカウントの管理について
Monaca2023年12月1日
ようやく全ての主要ブラウザで使用可能になるCSSの擬似クラス:hasを使ってみよう
その他2023年11月22日
「アシアルnote(旧:エンジニアリングで世界をちょっとよくするノート)」のデザインを一部リニューアルした話
UX/UI2023年11月17日
vuejs-template/webpackをwebpack3からwebpack4へアップデートする方法について
ノウハウ・TIPS2023年11月13日9月/10月社内Tech勉強会レポート – NodeJS/Privacy Sandbox API/3rdPartyCookie/NodeJS/PromiseAll/cascae/
その他2023年11月6日Monaca Dashboardの機能紹介
Monaca2023年11月1日8月社内Tech勉強会レポート – NextJS13/React18/Vercel/Mountpoint for Amazon S3/Planet Scale Boost
その他2023年10月7日AndroidビルドのAndroidManifest.xml設定重複エラーについて
Monaca2023年10月2日
VSCode の Local Port Forwarding を試してみました
テクノロジー2023年9月25日
Dockerだけではない: Podman、LXD、ZeroVMを含む主要なコンテナ技術を探る
テクノロジー2023年9月14日
分散型SNS, Fediverse, ActivityPub, Webfingerについて調べてみた。
テクノロジー2023年9月1日Cordova 12の注意点について
Monaca2023年9月1日
FedCM (Fedetated Credential Management API) 入門:進化したログイン方式を紹介
テクノロジー2023年8月21日MonacaクラウドIDEのオプション機能について
Monaca2023年8月1日
Apple Vision Proで変わるWebサイトのデザインとナビゲーション
UX/UI2023年7月28日
「エンジニア向けAI活用研修」を実施しました
テクノロジー2023年7月13日
PAGE TOP

アシアルの中の人が
技術と想いのたけをつづるブログ

日々の活動や取り組み、
アシアルのカルチャーを紹介




