




「TOPS」を計算してみよう 〜 AI対応PCの性能指標
エンジニアの又川(@n_matagawa)です。
皆さんは AI 対応 PC の性能指標に使われる「TOPS」という単位をご存知でしょうか?最近では Microsoft が発表した Copilot+ PC の性能要件である「40 TOPS」が話題になりましたね。
これから PC を買う方はその PC が 40 TOPS を超えているのか気になると思います。
そこで、この記事では「TOPS」の定義と、具体的な計算方法を解説したいと思います。
前提知識: TFLOPS とは
スーパーコンピュータの性能を測る指標として、「TFLOPS(テラフロップス)」というものがあります。「TFLOPS」は「Tera FLoating-point OPerations per Second」の略で、1秒間に何兆回の浮動小数点演算(加算・乗算のみ対象)ができるかを表すものです(*1)。
スーパーコンピュータや PC、スマホを始めとしたコンピュータの中では、加減乗除などの演算(operation)を行う ALU などの部品が1秒間に数十億回の周期(=数 GHz)で動いています。
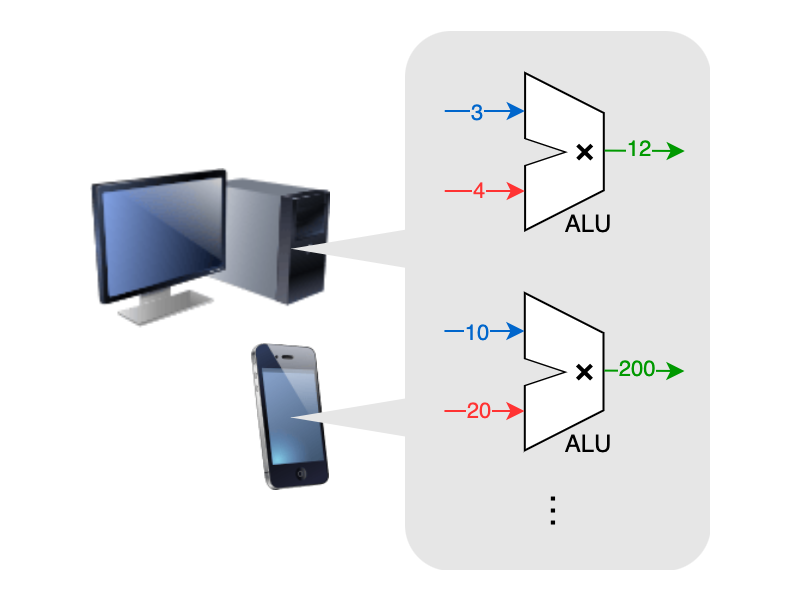
浮動小数点演算も ALU とその他の素子の組み合わせで実現されています。その浮動小数点演算の回数を数えたものが「TFLOPS」であるというわけです。
TOPS とは
では「TFLOPS」から「FL」が抜け落ちた「TOPS」は何なのかと言うと、1秒間に何兆回の整数演算(加算・乗算のみ対象)ができるかを表します。
精度は?
整数演算と言っても 8-bit, 16-bit, 32-bit, 64-bit など色々な精度での演算があります。「TOPS とはどの精度での整数演算のことを言っているのか?」というのが当然の疑問として上がると思います。
結論から言うと、AI分野における「TOPS」は、8-bit 精度(INT8)の整数演算の回数を表��します。これは厳密な定義があるものではなく、AI分野における業界標準であると Qualcomm が説明しています(*2)。
また、NVIDIA は一般の「TOPS」と区別するためか、同社サイトにて 8-bit 精度の整数演算回数に対して「AI TOPS」という単位を使用しています(*3)。
何で整数演算なの?
次に上がる疑問としては「ニューラルネットワークを扱うのがメインの AI 分野で、なぜ浮動小数点演算ではなく整数演算の性能をアピールするのか?」があると思いますが、これには非常にややこしい事情があります。
実は 2023 年に入ってから、学習(training)には浮動小数点演算を使うものの、推論(inference)には整数演算を使うようになったからです(量子化(quantization)と呼ばれる手法です)。
その辺りの事情は以下の記事で分かりやすく解説されているので、気になる方は以下を参照されることをお勧めします。
「Copilot+ PC」登場でもう「AI PC」も時代遅れ!? “NPU”、“40TOPS”など要件の疑問に迫る【イニシャルB】 - INTERNET Watch
https://internet.watch.impress.co.jp/docs/column/shimizu/1600748.html
TOPS の計算
では本題である TOPS の計算に入りましょう。
TOPS は CPU, GPU, TPU, NPU など様々なパーツやシステム全体に対して定義できます。
今回は GPU を例に TOPS を計算してみましょう。
NVIDIA GeForce RTX 4090 の CUDA コア利用時の TOPS
まずは NVIDIA 社のコンシューマ向け主力製品である GeForce RTX 4090 (2022/10/12 発売) の TOPS を計算してみましょう。
GeForce RTX 4090 には CUDA コア という演算ユニットが搭載されています。
まずは1個の CUDA コアがどんな演算能力をもっているのか調べてみましょう。
CUDA コアの力
以下は GeForce RTX 4090 の中に 128 個入っている Streaming Multiprocessor (SM) の拡大図です。「FP32/INT32」「FP32」などと書いてある部分が CUDA コアの集まりに相当します。

TOPS の算出
この CUDA コアを使うと、一度の入力で1回の整数演算ができます。これは 1 OP の演算に相当します。そしてホワイトペーパーによると GeForce RTX 4090 は CUDA コアを 16384 個持っていますので、 一度の入力で1 [OP] * 16384 [core] = 16384 [OP] の演算が発生します。
では1秒間に何回この入力が行われるのかですが、ホワイトペーパーによると GeForce RTX 4090 の GPU ブーストクロックは 2.52 GHz で、毎秒 25.2 億回の入力が行われます。
すると以下の計算式から、
16384 [OP] × 2.52 [GHz] ≒ 41.3 [TOPS] のように 41.3 TOPS が導かれます。これはホワイトペーパーの「Peak INT32 TOPS (non-Tensor)」の値と一致します。(※CUDA で INT8 演算を行うには DP4A 命令などを使う必要があるためひとまず INT32 での TOPS を導いています。)
NVIDIA GeForce RTX 4090 の Tensor コア利用時の TOPS
41.3 TOPS というのは Copilot+ PC の要件をギリギリ満たす値です。定価 $1599.00 の GPU がたったこれだけの TOPS しか出せないというのはおかしいですよね?
それもそのはず、GeForce RTX 4090 には CUDA コア以外にも Tensor コアが存在します。Tensor コアはAI推論に特化したコアで、AI推論では通常この Tensor コアを使用します。
Tensor コアの絶大な力
では、1個の Tensor コアがどんな演算能力をもっているのか調べてみましょう。Tensor コアは CUDA コアと異なり、混合精度演算と呼ばれる低精度の4x4行列演算を1クロックサイクルで行うことができます。
以下は Tensor コアが行う4x4行列計算の概念図です。右端にある 3D の図に着目してください。左奥側にある16個のパネルが入力行列A、右奥側にある16個のパネルが入力行列B、下側にある16個のパネルが次々と出力される出力行列Dを表しています。

行列演算は複数回の乗算と加算によって構成されるため、それが1クロックサイクルで行えると凄まじい OP 数になります。Tensor コアが速い理由はここにあります。
TOPS の算出
Tensor コア (4th Gen) では1クロックサイクルあたり平均 512 回の INT8 演算を実行できるようです(*4)。これは 512 OP の演算に相当します。そしてホワイトペーパーによると GeForce RTX 4090 は Tensor コアを 512 個持ってい��ますので、一度の入力で 512 [OP] * 512 [core] = 262144 [OP] の演算が発生します。
GeForce RTX 4090 の GPU ブーストクロックは 2.52 GHz です。すると、以下の計算式から、
262144 [OP] × 2.52 [GHz] ≒ 660.6 [TOPS] のように 660.6 TOPS が導かれます。これはホワイトペーパーの「Peak INT8 Tensor TOPS」の値と一致します。
Sparsity Feature
ちなみに、入力データが疎行列である場合��に速度が2倍になる Sparsity Feature を利用すると演算能力は 1321.2 TOPS まで向上します。製品ページなどではこの値がアピールされていることが多いです。
TOPS の身近な例
身近な例として MacBook Pro (14-inch, Nov 2023) の TOPS を挙げておきます。MacBook Pro の製品ページを見ると以下のような記述があります。
Over 18 trillion operations per second
An enhanced 16-core Neural Engine accelerates popular machine learning models.
https://www.apple.com/macbook-pro/ (2024/08/14 閲覧)
上記の通り、MacBook Pro (14-inch, Nov 2023) の Neural Engine の整数演算性能は 18 TOPS とされています。(M3, M3 Pro, M3 Max で違いがあるのかは不明です。また、計算式も不明です。)
最新の MacBook Pro ですらこの値なので、Copilot+ PC の要件である 40 TOPS はそれなりに高い数値といえます。
TOPS の注意点
仕様として記載される TOPS は演算ユニットだけに着目したもので、あくまで理論値です。実際のAI処理では、様々な事情により1秒間に処理できる演算がカタログスペックよりも少なくなることがあります。
実例
以下は NVIDIA GeForce RTX 4090 のボード表面の写真です。

写真を見る限り、GPU と VRAM の配置は以下のようになっています。
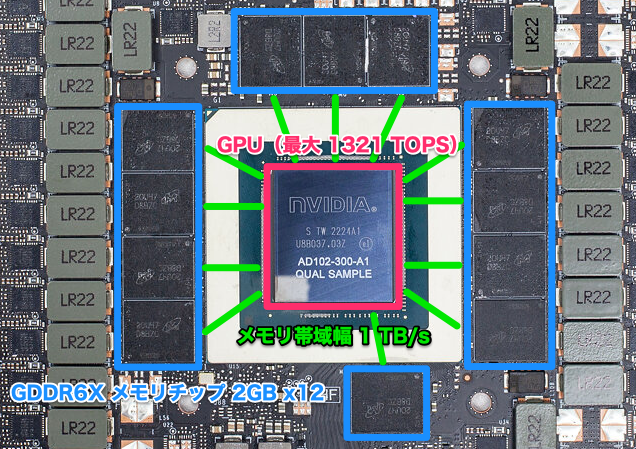
AI推論を行う時は、上記画像の青枠(VRAM)の中に AI モデルのパラメータと計算結果を載せていくことになります。ここでいくつかの注意が必要になります。
GPU から VRAM へのアクセスは遅い
GPU は最大で 1,321 TB/s の速度でデータを処理できるのに対して、GPU と VRAM の間のメモリ帯域幅は 1 TB/s しかありません。つまり、メモリ帯域幅がボトルネックになって GPU の演算ユニットの力が発揮しきれないことがあります。
L1, L2 データキャッシュはあるけども……
もしAIモデルが都合の良い設計になっていて VRAM 上の同じ値を何度も使い回す機会があれば、GPU 内の L1 データキャッシュや L2 データキャッシュのヒット率が 100 % に近くなり、カタログスペックに近い性能が出ます。
しかし、VRAM 上の同じ値を使い回す機会がない場合、キャッシュのヒット率が 0 % に近くなり、性能は 1 TOPS 以下まで下がる可能性があります。これは CPU の L1〜L3 キャッシュを OFF にすると性能が100分の1以下になるのと同じです。
つまり、キャッシュヒット率やワークロード(=処理の内容)によっても GPU の演算ユニットの力が発揮しきれないことがあるということです。
メモリ帯域幅・キャッシュ・ワークロードに注意
上記のように、AI推論における実��際の性能は (1) VRAM とのメモリ帯域幅 や (2) GPU のキャッシュヒット率、また、(3) どのようなワークロードであるか、によって大きく左右されます。これは GPU 以外の CPU や NPU のようなパーツについても同様です。
製品スペックなどに載っている TOPS はあくまで理論値であることに留意し、上記の点に注意を払ってください。
おわりに
今回は TOPS の定義と具体的な計算方法、そして注意点についてブログを書いてみました。
皆さんも手持ちの CPU や GPU の TOPS(理論値)を計算してみてください。計算方法は上記と全く同じです。
数ヶ月で状況が変わるAI分野に対して、アシアルでは開発やデザイン、事務業務など、立場によらずAIを積極的に理解・活用する取り組みを行っています。興味のある方は会社情報や採用情報もご覧ください。
ではまた!
脚注
(*1) https://top500.org/resources/frequently-asked-questions/
(*2) https://www.qualcomm.com/news/onq/2024/04/a-guide-to-ai-tops-and-npu-performance-metrics
(*3) https://www.google.com/search?q=%22AI+TOPS%22+site%3Anvidia.com
(*4) 660.6 TOPS から逆算して得た��値です。
























