




GPT-1 から GPT-5.2 まで: LLM の特殊トークン徹底解説【2025年12月最新】
エンジニアの又川です。
皆さんは LLM (大規模言語モデル) の 「特殊トークン」 をご存知でしょうか? ChatGPT や Claude などを使っていると意識することは少ないかもしれませんが、実はモデルの内部では 「ここからユーザの発話だよ」「ここで思考を始めるよ」 といった制御情報を伝えるための特別なトークンが使われています。
この記事では、 GPT-1 や BERT、GPT-2 といった黎明期の Transformer モデルから始まり、 T5 のようなテキスト補完から脱却した Transformer モデル、 GPT-3 のような初期の LLM、 InstructGPT のような指示追従型 LLM、 GPT-3.5 Turbo のようなチャット機能付き LLM、 GPT-4 のようなマルチモーダル LLM、そして GPT-5.2 のような思考機能付き LLM (Reasoning モデル) まで、各モデルがどのような特殊トークンを使っているのかを具体例とともに紹介します。
前提知識: トークン
言語モデルはテキストを トークン (token) という単位に分割して処理します。トークンは必ずしも単語と一致するわけではなく、単語の一部分や文字、バイト列の場合もあります。
モデルが認識できるトークンの一覧を ボキャブラリ (vocabulary) と呼び、各トークンには一意の ID が割り当てられています。ボキャブラリのサイズは有限です。
前提知識: トークナイズ
テキストをトークン列に分割する処理を トークナイズ (tokenize) と呼びます。
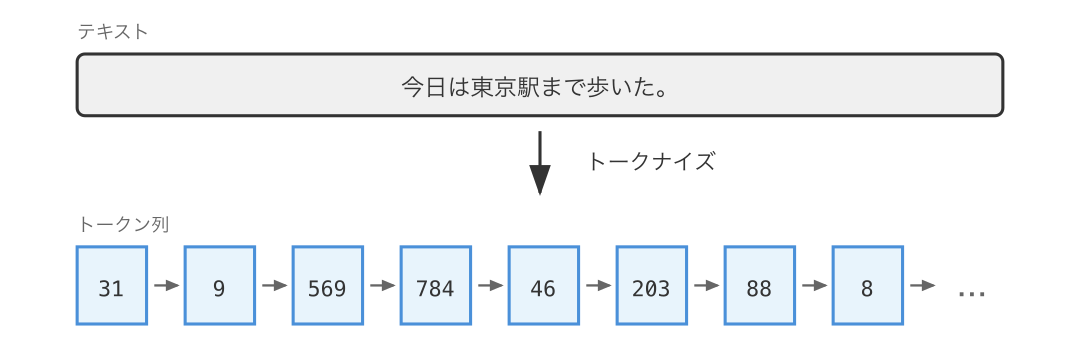
上の図には書かれていませんが、トークナイズを行うツールを トークナイザ (tokenizer) と呼びます。
トーク��ナイズについては、国語の授業で習った品詞分解のように「単語や意味のある単位に分割する」というイメージを持っている方が多いのではないでしょうか? 「名詞」「動詞」「助詞」みたいに分けるあれです。
しかし、言語モデルでのトークナイズはそんなに単純ではありません。トークナイズにはいくつかの トークナイズ方式 があり、それぞれ動作原理が異なります。
前提知識: トークナイズ方式
トークナイズ方式にはざっと以下のようなものがあります。順に解説していきます。
| 方式名 | 採用モデル |
|---|---|
| WordPiece | BERT など |
| BPE (Byte Pair Encoding) | GPT 系モデル, Meta 系モデルなど |
| バイトレベル BPE | GPT-2 以降など |
| Unigram | Google 系モデル・日本語モデルなど |
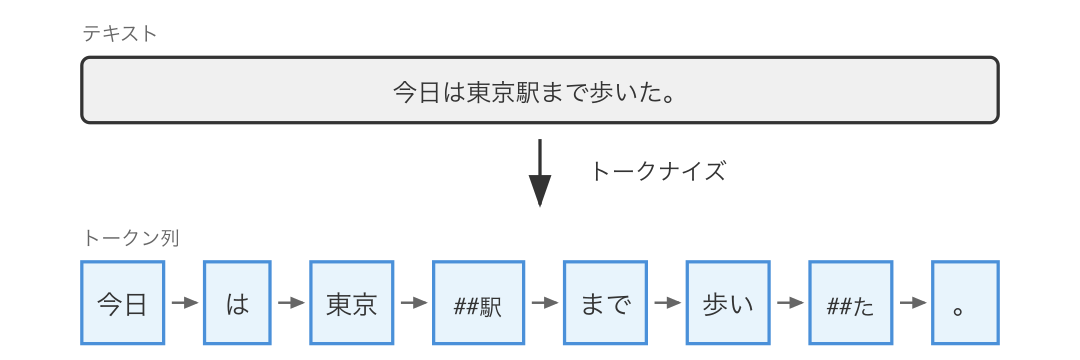
WordPiece 方式
WordPiece は最も直感的な方式です。基本的には単語単位で分割し、辞書にない単語は サブワード(部分文字列) に分解されます。
"playing" → "play" + "##ing"
"unhappiness" → "un" + "##happi" + "##ness"
"東京駅" → "東京" + "##駅"
"歩いた" → "歩い" + "##た"「##」は「前のトークンに続く」という意味です。
BPE (Byte Pair Encoding) 方式
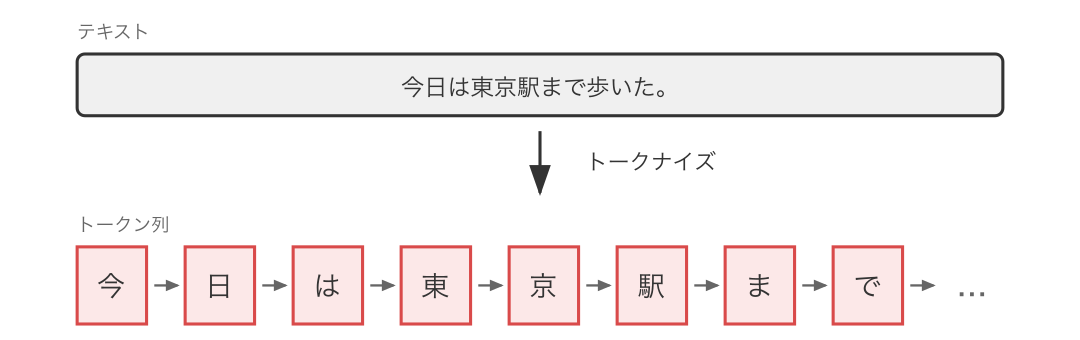
BPE は全く異なるアプローチを取ります。
まず、初期状態の BPE トークナイザではすべてのトークンが 1 文字です。でもこれだと「こんにちは」は 5 トークン、長い文章はとんでもないトークン数になってしまいますよね。非効率です。
そこで BPE では、学習データを見ながらよく出現する文字の組み合わせを新しいトークンとして採用して、トークナイザを効率化していきます。
学習データで "今日" がよく出現 → "今日" を新しいトークンとして追加
学習データで "今日は" がよく出現 → "今日は" を新しいトークンとして追加
...こうすることで、頻出する文字列は 1 トークンで表現でき、全体のトークン数を削減できます。
つまり、意味ではなく出現頻度でトークンが決まるのです。その結果、「今日は」は 1 トークンになりますが、珍しい単語は細切れのままになります。
バイトレベル BPE 方式
GPT-2 以降で採用されている方式です (*3)。通常の BPE は文字単位で処理しますが、バイトレベル BPE は UTF-8 文字列をバイト単位で処理します。0x00〜0xff の 256 種類のバイトすべてがボキャブラリに含まれているため、どんな入力でも必ずバイト単位に分解できます。これにより未知語が発生しなくなり、あらゆるテキストをトークン化できます。
特に OpenAI は高速なバイトレベル BPE ライブラリとして tiktoken (*4) をオープンソースで開発・公開しており、GPT 系などの主要モデルで使用しています。
Unigram 方式
Unigram は サブワード確率モデル に基づくトークナイズ方式です。
BPE のように頻出ペアを順に結合するのではなく、あらかじめ大量のサブワード候補に確率を割り当て、文全体を最も高い確率で再現できるようなサブワード列を選びます。そのため、日本語のような単語境界の曖昧な言語に特に適しています。
SentencePiece(ライ�ブラリ)
トークナイズ方式ではありませんがあまりにもよく使われるので紹介しておきます。
SentencePiece (*5) はトークナイズのための ライブラリ です。SentencePiece を使うと 英語のようなスペースのある言語と日本語のようなスペースのない言語を統一的に扱う ことができるため(言語非依存)、スペースを含む生テキストから直接学習できるのが大きな特徴です。内部で BPE 方式や Unigram 方式などを実装しているため、好きなトークナイズ方式を簡単に利用できます。
他にも様々なトークナイズ方式が考案されています。
さて、前提知識を確認したので、本題の特殊トークンの話題に入っていきましょう。具体的なモデルを見ながら説明していきます。
黎明期の Transformer モデルと、特殊トークン
GPT-1 (OpenAI, 2018年6月) - 約1.2億パラメータ
初期の Transformer ベースの言語モデルとして有名なのが GPT-1 です(*1)。
トークナイザは BPE 方式で、ボキャブラリサイズは約 40,000 です。英語専用のモデルなので、日本語などは扱えません。
GPT-1 は自己回帰型の言語モデルなので、与えられたテキストの続きを生成します。例えば「This is a」というテキストを与えると、続きを予測して「This is a pen.」のような文章を生成します。
トークナイズと、その逆の操作である デトークナイズ (detokenize) も含めて図示すると以下のようになります。
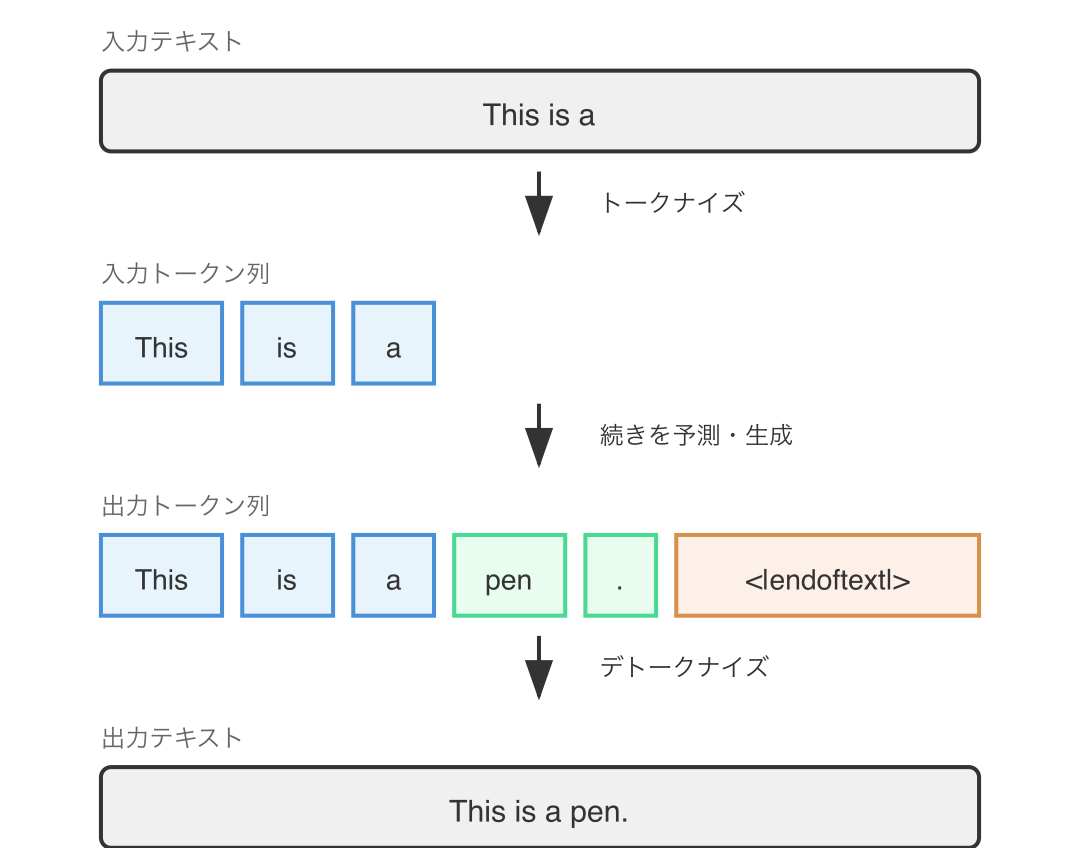
ここで 特殊トークン (special token) が登場します。特殊トークンとは、通常の単語トークンとは別に予約されたトークンで、文章の構造や会話のメタ情報をモデルに伝えるために使われるものです。
生成はいつまでも続くわけではありません。GPT-1 では <|endoftext|> という文字列からなるトークンが特殊トークンとしてボキャブラリに登録されており、学習データや設定に基づいて適切なタイミングでこのトークンが出力され、生成が終了します。より具体的には、<|endoftext|> に対応するトークン ID を検出した時に次のトークンの生成を中止します。
特殊トークンに対応する文字列(<|endoftext|> など)は デトークナイズ時に除去する ため、出力テキストには含まれません。
<|endoftext|> のような特殊トークンは慣習的に EOS (End-Of-Sequence) トークンと呼ばれ、シーケンスの終了を示します。
GPT-1 にはもうひとつ、<unk>(未知語トークン)があります(*2)。通常の BPE ではボキャブラリにない文字(珍しい Unicode 文字や絵文字など)が入力されると、この <unk> に変換されます。
GPT-1 の特殊トークンは <unk> と <|endoftext|> だけというシンプルな設計です。
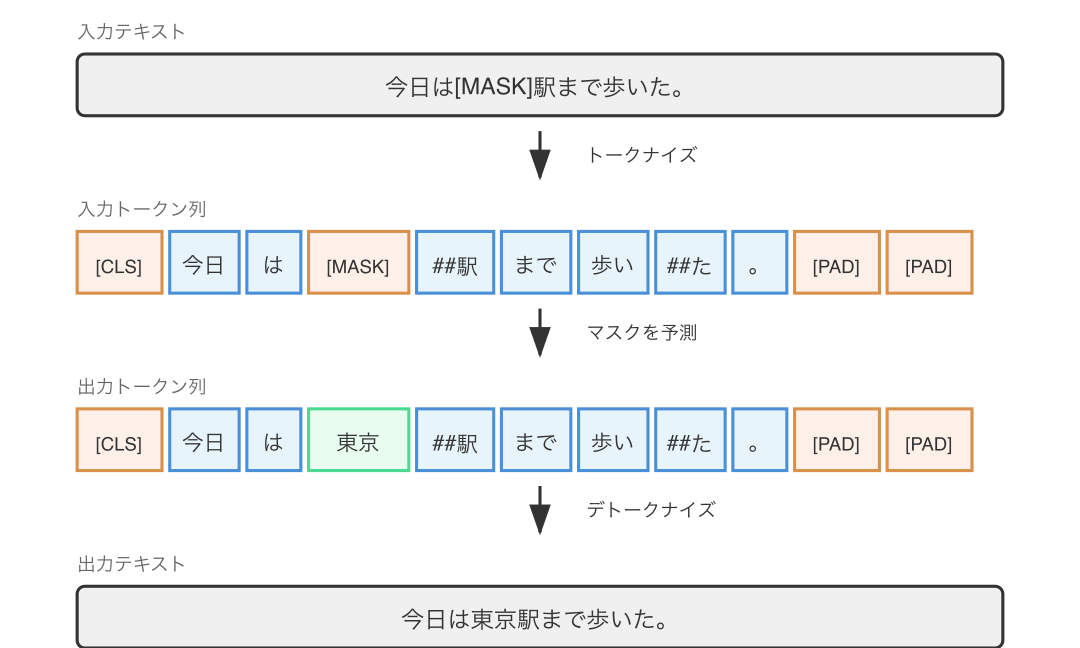
BERT(Google, 2018年10月) - 約1.1〜3.4億パラメータ
BERT はエンコーダ型 Transformer として、特殊トークンの設計に大きな影響を与えたモデルです。トークナイズ方式は WordPiece で、ボキャブラリサイズは約 30,000 です。
| 特殊トークン | 説明 |
|---|---|
[CLS] | 文の先頭に付与。分類タスクで文全体の表現を取得するために使用 |
[SEP] | 文の区切り。2文入力タスク(質問応答など)で文を分離 |
[MASK] | マスク言語モデル(MLM)で予測対象の位置を示す |
[PAD] | バッチ処理時に長さを揃えるためのパディング |
[UNK] | 未知語トークン |
BERT は「次の単語を予測する」GPT とは異なり、「マスクされた単語を予測する」という双方向の学習を行います。この設計のために [MASK] という特殊トークンが必要でした。
GPT-2 (OpenAI, 2019年2月) - 約1.2〜15億パラメータ
GPT-2 は GPT-1 の約 10 倍のパラメータ数を持つモデルです。トークナイズ方式がバイトレベル BPE に変更され、未知語が発生しなくなったため、GPT-1 にあった <unk> は不要になりました (*3)。特殊トークンは <|endoftext|> のみです。
テキスト補完からの脱却と、特殊トークン
GPT-2 や BERT が出た頃は、文章の続きを予測したり(GPT-2)、文章を穴埋めしたり(BERT)するのが限界でしたが、その後、 パラメータ数の増大によるモデル性能向上 や 発想の転換 によって徐々に様相が変わっていきます。
T5 (Google, 2019年10月) - 約0.6〜110億パラメータ
T5(Text-to-Text Transfer Transformer) はエンコーダ・デコーダ型 Transformer として、入力と出力が構造的に分離されているモデルです(*6)。トークナイズ方式は Unigram で、ボキャブラリサイズは 32,000 です。
| 特殊トークン | 説明 |
|---|---|
</s> | シーケンスの終了(EOS) |
<pad> | パディング |
<unk> | 未知語 |
T5 はそれまでとは全く異なる発想の使い方をする言語モデルです。
以前は「入力テキストをエンコードして、分類器や翻訳器にかけて出力を得る」というのが自然言語処理における常識でしたが、T5 は 「分類や翻訳などといった指示も入力テキストに含めてしまう」 という使い方を発明しました。この発想の転換により、後に言語モデルへの入力テキストは プロンプト (prompt)、出力テキストは レスポンス (response) と呼ばれるようになっていきます。
以下の例では、「That is good.」という英語の文章をドイツ語に翻訳しています。T5 の論文では「translate English to German:」の部分を タスクプレフィックス (task prefix) と呼んでいます(*6)。
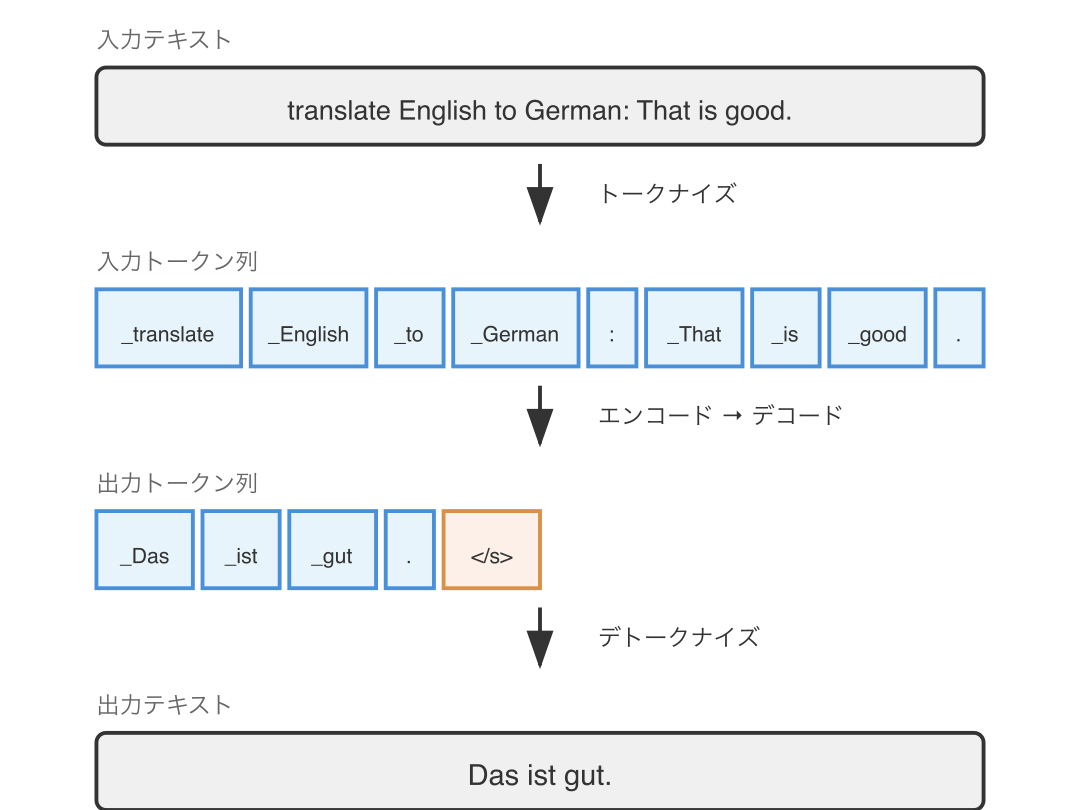
図中の _ は SentencePiece で単語の先頭を示すマーカーです(正確には ▁ (U+2581) ですが、表示の都合上 _ で代用しています)。
しかし注目してほしいのは、特殊トークンとしては </s> しか使われていない ことです。T5 は画期的な言語モデルの使い方を発明しましたが、この時点では まだ新たな特殊トークンは必要なかった のです。
GPT-3 (OpenAI, 2020年5月) - 約1.25〜1750億パラメータ
GPT-3 は GPT-2 の 100 倍以上のパラメータ数を持つモデルです。1000 億パラメータを超える言語モデルが LLM (Large Language Model) と呼ばれますので(*7)、GPT-3 は最初の LLM と言えます。トークナイザはバイトレベル BPE 方式で、ボキャブラリサイズは 50,257 です (*3)。
GPT-3 はそれまでできなかった予測を可能としました。典型例が以下のような入力テキストに対する予測(今日で言う インコンテキスト学習)です。
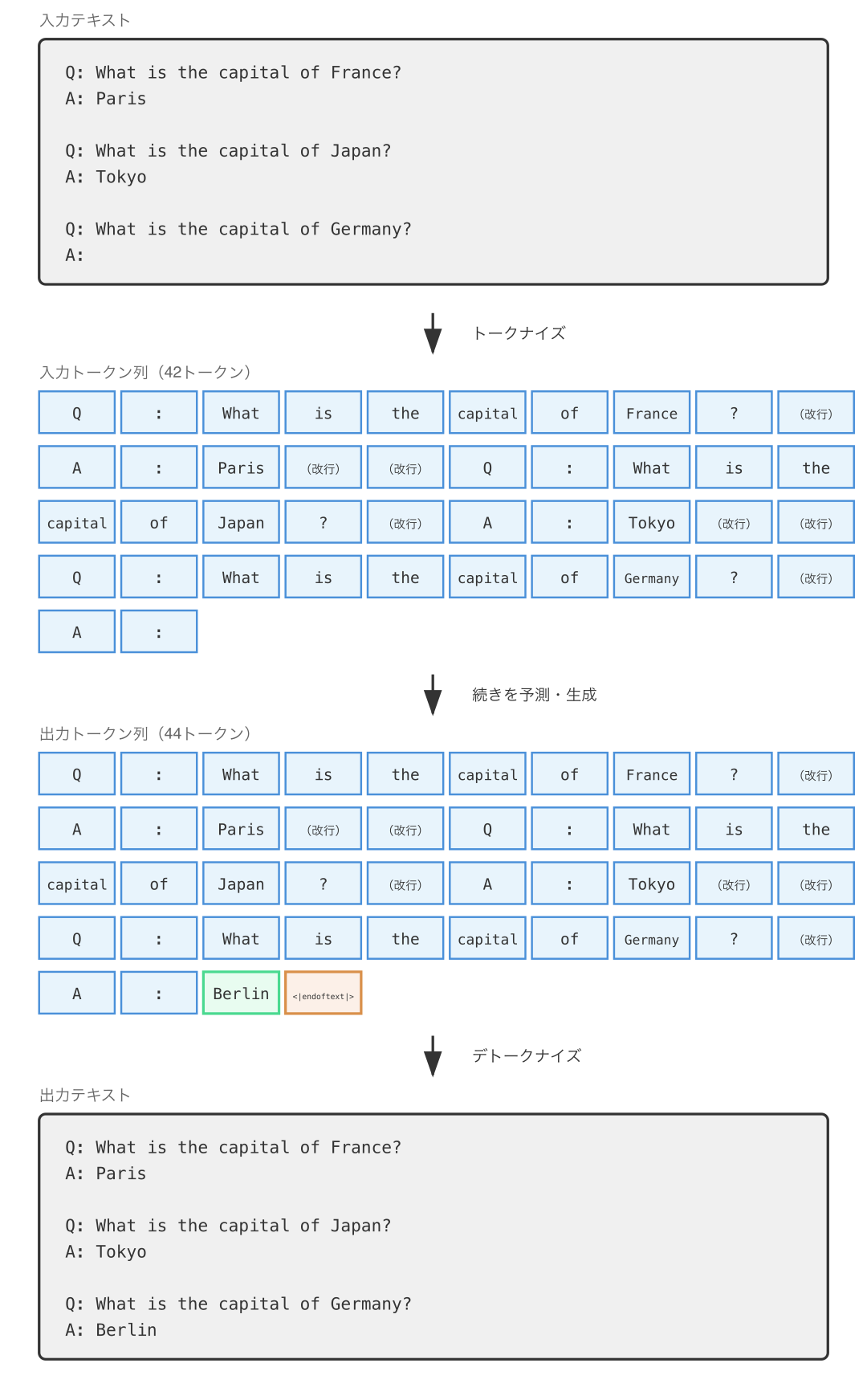
しかし特殊トークンの観点では、GPT-3 は <|endoftext|> しか持っていませんでした。この時点ですら、特殊トークンの追加はまだ必要なかったのです。
InstructGPT (OpenAI, 2022年1月) - 約13〜1750億パラメータ
GPT-3 には欠点があり、 T5 のように指示(命令文)に答えることができませんでした。 GPT-3 はあくまで「次のトー�クンを予測する」ことに特化していたからです。命令文を与えると「似たような命令文」を続きとして生成してしまいます。
そこで OpenAI は GPT-3 をベースに 指示への応答精度を高めた InstructGPT を開発しました。以下は同じ入力テキストを与えた場合の予測テキストの比較です(*8)。
入力テキスト:
Explain the moon landing to a 6 year old in a few sentences.GPT-3 の予測テキスト:
Explain the theory of gravity to a 6 year old.
Explain the theory of relativity to a 6 year old in a few sentences.
Explain the big bang theory to a 6 year old.
Explain evolution to a 6 year old.InstructGPT の予測テキスト:
People went to the moon, and they took pictures of what they saw, and sent them back to the earth so we could all see them.GPT-3 が「似たような命令文」を生成してしまう一方で、InstructGPT は「指示に従う」ことを学習しているため、適切な応答を返せるようになっています。
しかし特殊トークンの観点では、 InstructGPT の特殊トークンは <|endoftext|> のみ でした。この時点でもなお特殊トークンの追加は必要なかったのです。InstructGPT は 入力テキストと予測テキストの境界 を指示と応答の境界として巧みに利用して問題を解決してしまったのです。
チャット機能付き LLM の登場と、特殊トークン
T5 や GPT-3、InstructGPT は単純なテキスト補完からの脱却を果たしましたが、そこでは新たな特殊トークンの出番はありませんでした。
しかしここで <|endoftext|> の限界が訪れます。会話の応酬、つまり チャット の登場で��す。
チャット機能という初めての壁
T5 や GPT-3、InstructGPT の出力テキストはいずれも </s> や <|endoftext|> などの特殊トークンで終わってしまいます。「相手(モデル)が回答したらそこで終わり」 です。これを シングルターン会話 と言います。
しかしシングルターン会話では味気ないので、「相手(モデル)の回答を 踏まえた上で さらに指示したり質問したりし、モデルから返ってきた回答を読む」ということがしたくなってきます。こういった会話を マルチターン会話 と言います。それを平たく言ったものが チャット です。
さて、一見簡単なマルチターン会話ですが、特殊トークンが <|endoftext|> だけの今までのやり方で実現できそうでしょうか?そうです、 ほぼ無理 です。 <|endoftext|> で発言を区切っていくことはできるかもしれませんが、 どこからどこまでが誰の発言なのか が分からなくなってしまいます。マルチターン会話の実現は <|endoftext|> のワンオペと非常に相性が悪いのです。
そこで OpenAI を含む研究コミュニティは、GPT-3 や InstructGPT をベースにどのようにマルチターン会話を実現するか模索しました。
ChatML (OpenAI, 2022年頃開発, 2023年3月発表)
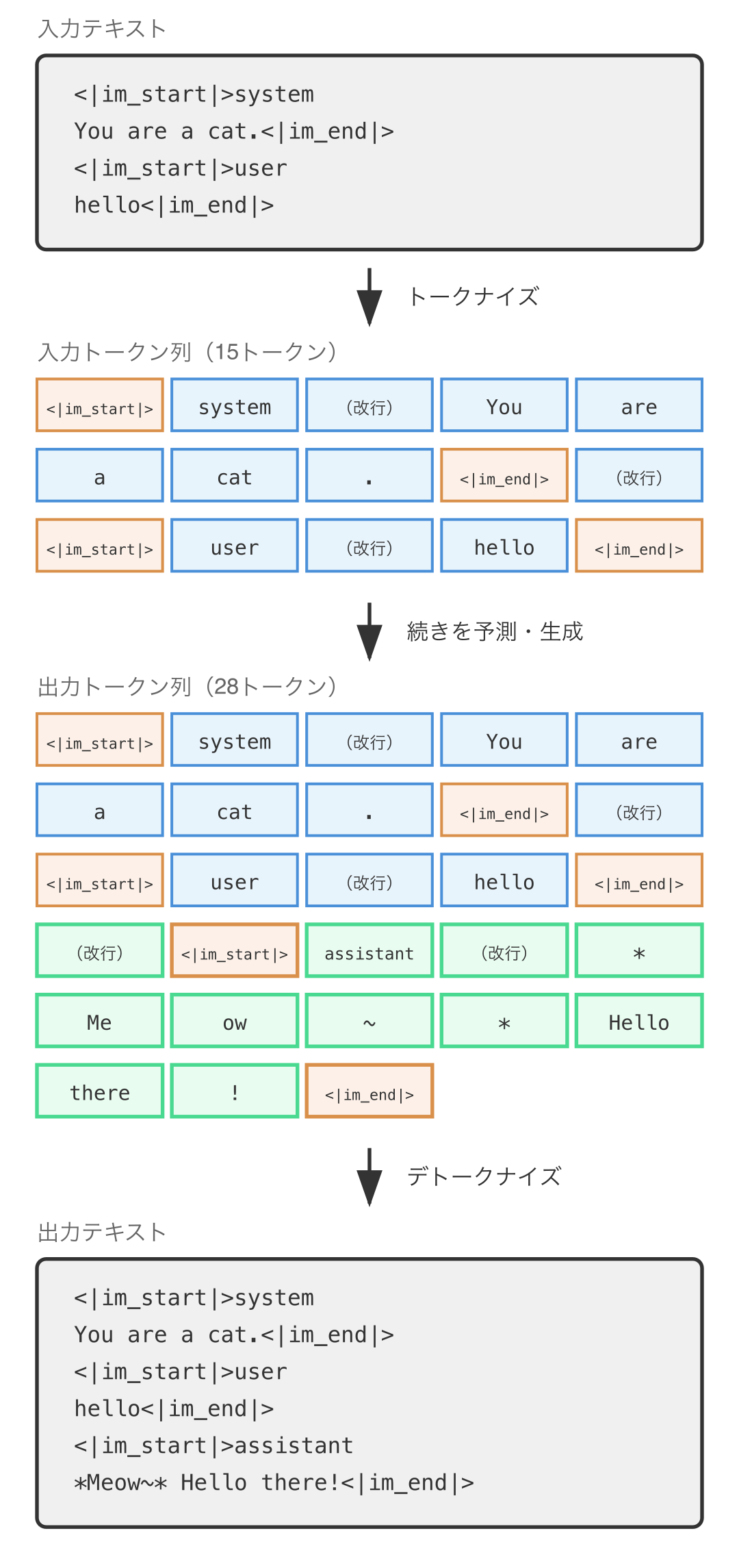
試行錯誤の結果、OpenAI は ChatML (Chat Markup Language) というマルチターン会話を記述するためのマークアップ言語を開発しました (*9)。以下は システム、ユーザ、そして アシスタント の3人による会話�を記述した ChatML です。システムはアシスタントを制御する存在で、アシスタントはユーザに応答する存在です。
<|im_start|>system
You are a cat.<|im_end|>
<|im_start|>user
hello<|im_end|>
<|im_start|>assistant
*Meow~* Hello there!<|im_end|>上の例ではまずシステムが「あなた(アシスタント)は猫です。」と言い、ユーザが「こんにちは」と言い、それに対してアシスタントが「にゃ〜ん!こんにちは!」と応答するマルチターン会話が記述されています。
さて、どこかで見たような文字列がありますよね?そうです、<|im_start|> と <|im_end|> は特殊トークンです。
| 特殊トークン | 説明 |
|---|---|
<|im_start|> | メッセージ(ロール名 + 発話内容)の開始 |
<|im_end|> | メッセージの終了 |
あとはこの ChatML で記述されたマルチターン会話を GPT-3 や InstructGPT の入力テキストとして投入すれば チャット機能付き LLM の完成です。
GPT-3.5 Turbo(OpenAI, 2022年11月) - パラメータ数非公開
GPT-3.5 Turbo は GPT-3.5 シリーズの一つで、ChatGPT のリリース時に使用されていた世界初のチャット機能付き LLM です。前述の ChatML 形式を採用し、マルチターン会話を実現しています。
トークナイザは GPT-2/GPT-3 と同じバイトレベル BPE ですが、エンコーディングが cl100k_base に更新され、ボキャブラリサイズは約 100,000 に拡大しています (*3)。
チャット用に最適化されているとの公式情報がありますが(*10)(*11)、詳細な学習方法は 公開されていないため現在も不明 です。
マルチモーダル LLM の登場と、特殊トークン
さて、ChatML のような特殊トークンの導入により LLM はマルチターン会話に対応しました。次に課題として上がったのは画像の理解です。
LLM の研究は単なるテキスト補完やチャット補完を超えて、物理学や医学の問題といった現実の問題を解くことに向かい始めました。そこでネックとなったのが文書中の写真や図、つまり画像を理解することでした。
特に、画像だけを入力してテキストで出力を得るのではなく、「この画像の興味深いところを説明して」などといった 画像とテキストが組み合わさった指示(マルチモーダルな指示) に対応することが求められました。
GPT-4(OpenAI, 2023年3月) - パラメータ数非公開
最初に画期的な成果を出したのは GPT-4 でした。
GPT-4 は言語理解の性能が圧倒的に向上しただけでなく、画像入力用の特殊トークンが導入され、それにより物理学や医学などといった現実の問題への対応力が飛躍的に高まりました。
しかし OpenAI は GPT-4 の仕組みについて「競争上の理由と安全上の理由から詳細を公開しない」と技術レポートで明言しました(*12)。そのため GPT-4 が画像入力用の特殊トークンとしてどのようなものを導入したかは 現在も不明 です。
この記事では代わりにオープンに公開されたマルチモーダル LLM を通して画像入力用の特殊トークンを説明していきます。
LLaVA(Wisconsin-Madison 他, 2023年4月) - 約70〜130億パラメータ
GPT-4 のリリースから約1ヶ月後、オープンソースのマルチモーダル LLM として LLaVA (Large Language and Vision Assistant) が公開されました(*13)。
トークナイザは BPE 方式で、ボキャブラリサイズは約 32,000 です。
| 特殊トークン | 説明 |
|---|---|
<image> | 画像の位置を示すプレースホルダ |
入力テキストの形式は以下の通りです。
USER: <image>
What's the content of the image?
ASSISTANT:<image> トークンは単なるプレースホルダであり、実行時には 視覚エンコーダー が画像を読み込んで出力した 576 個の画像トークンに置き換えられます。つまり、1枚の画像は内部的に 576 個のトークン列として LLM に入力されるのです。
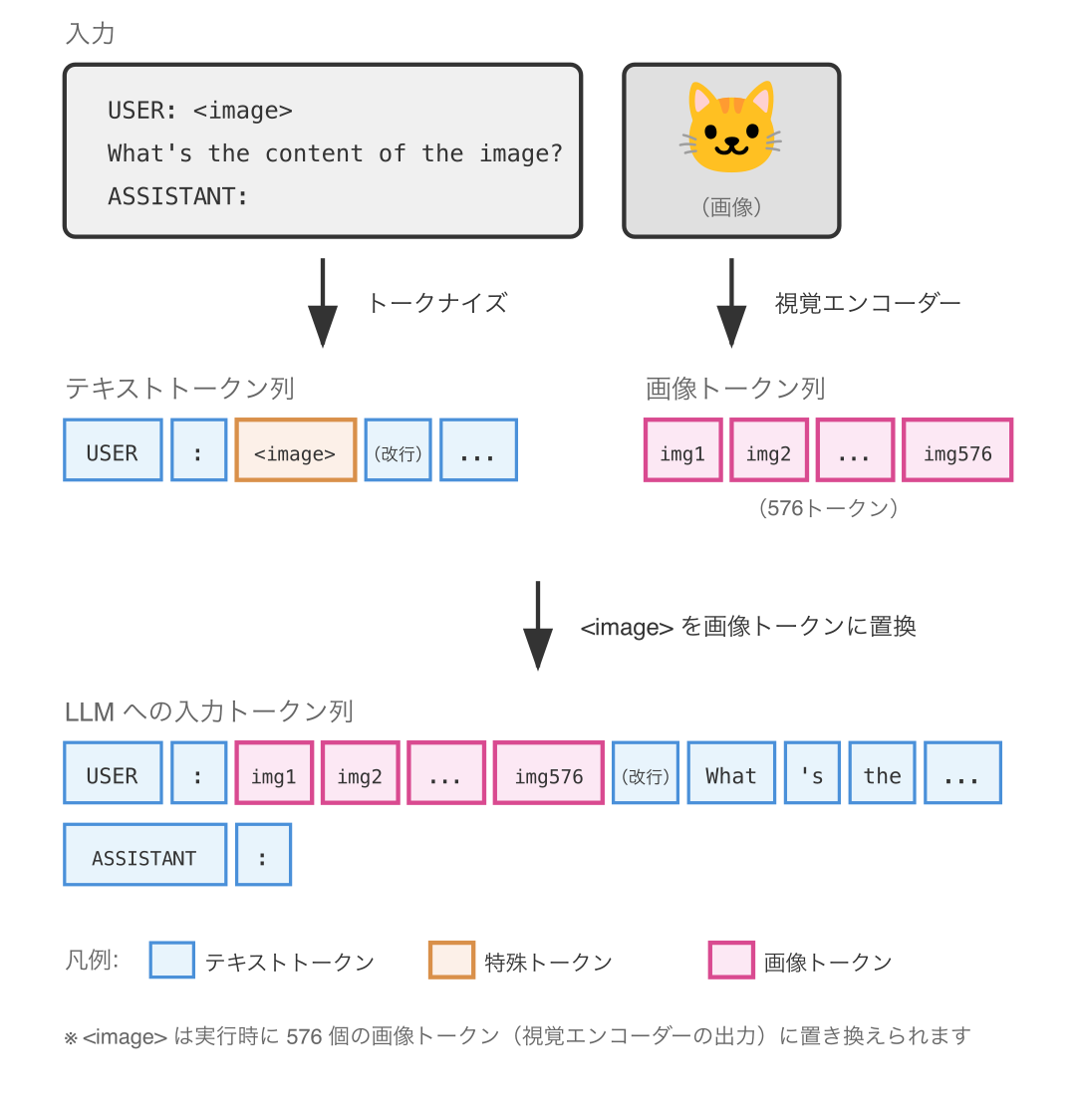
専門的には、画像は視覚エンコーダーによってベクトル表現に変換され、線形投影層を通じて テキストトークンと同じ次元 の埋め込みに変換されます。基本的に 画像は ID で表現できないので、画像トークンに ID はありません。
このように、マルチモーダル LLM で�は「画像をどこに挿入するか」を示すための特殊トークンが導入されています。GPT-4 も内部的には同様の仕組みを持っていると推測されますが、詳細は非公開のままです。
Reasoning モデルの登場と、特殊トークン
さて、LLM はテキストに加えて画像をも処理することができるようになりました。しかし、課題として残ったのは 思考の単純さ です。
GPT-4 によってかなりの改善はされましたが、それでも LLM が「考えたら分かるような明らかな誤り」(ハルシネーション)を起こす問題が残っていました。そこで、この頃は 思考連鎖(Chain of Thought) の工夫などといった プロンプトエンジニアリング によってユーザが LLM の思考を矯正する状況が続いていました。
しかし、「考えたら分かるような明らかな誤り」があるなら LLM に 考えさせれば良い のです。そこで登場したのが Reasoning モデル(RLM, LRM) です。
(Reasoning は日本語で言うところの「深く考えること」に相当しますが、「思考 (thinking)」や「推論 (inference)」などの訳語を使うと既存の用語と衝突するため、あえて訳さない 場合があります。この記事ではそのスタンスを取ります。)
Reasoning モデルの開発でも、特殊トークンが活躍することとなりました。
OpenAI o1(OpenAI, 2024年9月) - パラメータ数非公開
o1 は実質的な最初の Reasoning モデルです(*14)。トークナイザはバイトレベル BPE 方式で、エン��コーディングは o200k_base に更新され、ボキャブラリサイズは約 200,000 に拡大しています (*3)。
このモデルは 思考トークン (reasoning token) を導入し、モデルに一種の下書き用スクラッチパッドを与えた点が画期的でした(*15)。モデルは回答をいきなり出力する代わりに、内部で思考専用のトークン列を生成し、それを踏まえて最終回答を決定するようになったのです。
OpenAI の発表によれば、思考にトークン数をかければかけるほど性能が上がることが確認されており(*16)、この思想に基づいて o1 は訓練されました。具体的には、強化学習によって良い思考連鎖・推論ステップをモデル自身が生成・改善することを学習させるというアプローチが取られています(*17)。後続の o4-mini では少なくとも RFT (Reinforcement Fine-Tuning, 強化ファインチューニング) という方法が使われています(*18)。
しかし、具体的な特殊トークンは非公開です。API では思考トークンの内容は見えず、ChatGPT の UI では要約が表示されるのみです。
この記事では、オープンに公開された Reasoning モデルを通して思考用の特殊トークンを説明していきます。
Reasoning モデルの実装方法
OpenAI o1 によって「思考トークン」という概念とその高い性能は広く知られるようになりましたが、具体的な実装方法は非公開のままでした。各社やコミュニティは独自に Reasoning モデルの開発を模索していましたが、特殊トークンの形式まで含めてオープンに公開されたモデルはしばらくありませんでした。
そんな中、中国の DeepSeek-AI は OpenAI o1 と同等の性能を持つ Reasoning モデルをオープンに公開しました。それが DeepSeek-R1 です。
| モデル | 開発元 | 発表月 | リリース月 |
|---|---|---|---|
| o1 | OpenAI | 2024年9月 | 〃(プレビュー) |
| QwQ-32B-Preview | Alibaba (Qwen) | 2024年11月 | 〃 |
| Gemini 2.0 Flash Thinking | 2024年12月 | 〃 | |
| o3 | OpenAI | 2024年12月 | 2025年4月 |
| DeepSeek-R1 | DeepSeek-AI | 2025年1月 | 〃 |
| Claude 3.7 Sonnet (Extended Thinking) | Anthropic | 2025年2月 | 〃 |
| Llama 4 | Meta | 2025年4月 | 〃 |
| o4-mini | OpenAI | 2025年4月 | 〃 |
| Phi-4-reasoning | Microsoft | 2025年4月 | 〃 |
DeepSeek-R1(DeepSeek-AI, 2025年1月)- 約6710億パラメータ
DeepSeek-R1 (*19) は、特殊トークンを利用することで OpenAI の言う「思考トークン」を実現できることを証明した最初のオープンモデルとなりました。
| 特殊トークン(*20) | 説明 |
|---|---|
<|begin▁of▁sentence|> | 文の開始(BOS) |
<|end▁of▁sentence|> | 文の終了(EOS) |
<|▁pad▁|> | パディング |
<|User|> | ユーザメッセージの開始 |
<��|Assistant|> | アシスタントメッセージの開始 |
<|EOT|> | ターン終了(End of Turn) |
<think> | 思考の開始 |
</think> | 思考の終了 |
<|fim▁begin|> | Fill-in-the-Middle 開始 |
<|fim▁hole|> | Fill-in-the-Middle 穴(補完箇所) |
<|fim▁end|> | Fill-in-the-Middle 終了 |
<|tool▁calls▁begin|> | ツール呼び出し群の開始 |
<|tool▁calls▁end|> | ツール呼び出し群の終了 |
<|tool▁call▁begin|> | 個別ツール呼び出しの開始 |
<|tool▁call▁end|> | 個別ツール呼び出しの終了 |
<|tool▁sep|> | ツール区切り |
<|tool▁outputs▁begin|> | ツール出力群の開始 |
<|tool▁outputs▁end|> | ツール出力群の終了 |
<|tool▁output▁begin|> | 個別ツール出力の開始 |
<|tool▁output▁end|> | 個別ツール出力の終了 |
<|place▁holder▁no▁0|> 〜 <|place▁holder▁no▁797|> | プレースホルダー(798個、将来の拡張用) |
DeepSeek-R1 は以下の図のように動作します。
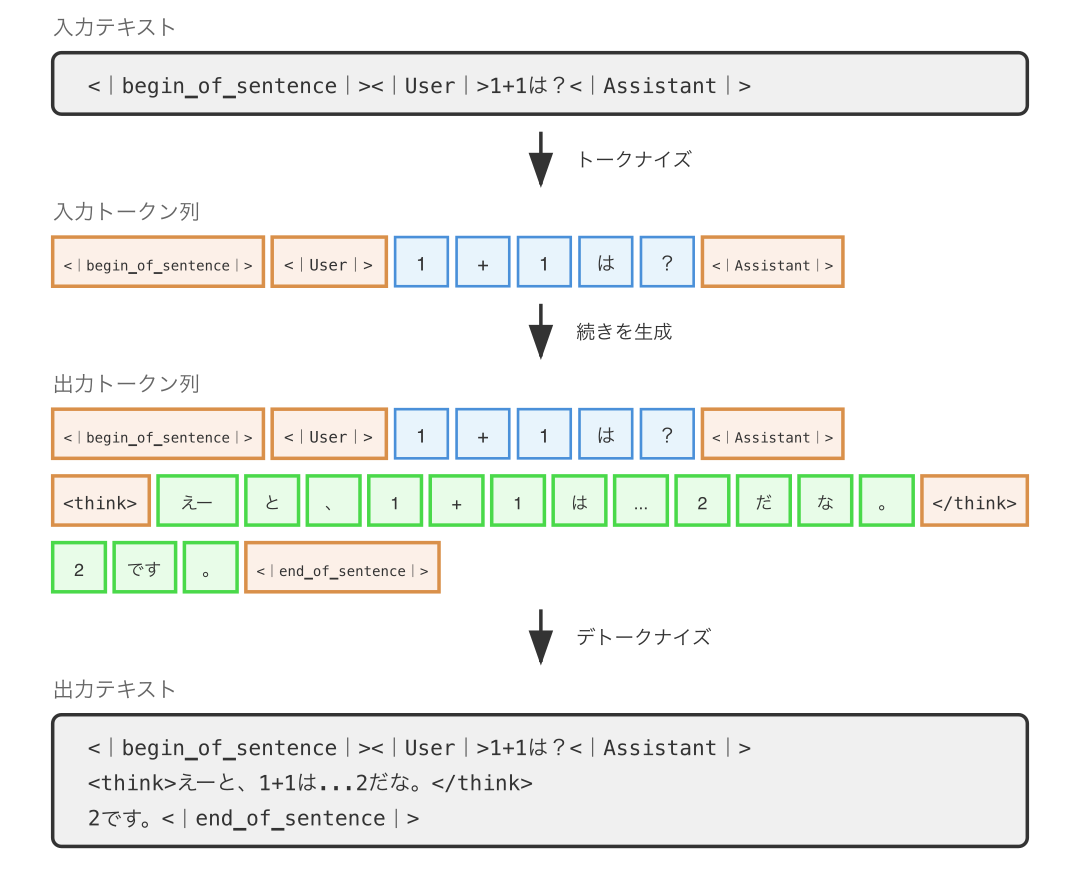
このように <think> タグで囲まれた範囲にモデルの思考プロセスが展開され、</think> 以降に実際の回答が出力されます。
DeepSeek-AI はその後以下のように新たなモデルを続々と公開しました。しかし特殊トークンに関しては DeepSeek-V3.2-Speciale(2025年12月1日)の時点でも |DSML|, <dsml:, </dsml:, <|search▁begin|>, <|search▁end|> が追加されたのみで、DeepSeek-R1 からほとんど変更はないようです(*21)。
| モデル | リリース日 | 備考 |
|---|---|---|
| DeepSeek-V3 | 2024年12月 | MoE アーキテクチャ(671B パラメータ、37B アクティブ) |
| DeepSeek-R1 | 2025年1月 | 思考トークンを公開した最初のオープンモデル |
| DeepSeek-V3-0324 | 2025年3月24日 | R1 の RL 技術を導入 |
| DeepSeek-V3.1 | 2025年8月 | V3 と R1 のハイブリッド |
| DeepSeek-V3.1-Terminus | 2025年9月22日 | |
| DeepSeek-V3.2-Exp | 2025年9月29日 | 実験版 |
| DeepSeek-V3.2 | 2025年12月1日 | V3.2-Exp の正式版 |
| DeepSeek-V3.2-Speciale | 2025年12月1日 | 思考特化版(API のみ) |
gpt-oss(OpenAI, 2025年8月) - 約210〜1170億パラメータ
gpt-oss (*22) は OpenAI が GPT-2 ぶりに公開したオープンウェイトのモデルです。
トークナイザはバイトレベル BPE 方式で、o200k_harmony エンコーディングが使用されており、ボキャブラリサイズは約 200,000 です (*3)。
gpt-oss は Harmony Response Format というプロンプト形式で訓練されており、会話構造、思考出力、関数呼び出しを構造化するための特殊トークンを持っています(*23)。
gpt-oss の公開と同時に Harmony Response Format のドキュメントも公開されたため、 OpenAI が Reasoning モデルにどのような特殊トークンを用いていたか が判明しました。
| 特殊トークン | 説明 |
|---|---|
<|start|> | メッセージの開始 |
<|end|> | メッセージの終了 |
<|message|> | ヘッダーからコンテンツへの遷移 |
<|channel|> | チャンネル情報への遷移 |
<|constrain|> | ツール呼び出しのデータ型定義 |
<|return|> | 応答完了(ストップトークン) |
<|call|> | ツール呼び出し(ストップトークン) |
Harmony Response Format では、メッセージにロール(system, developer, user, assistant, tool)とチャンネル(final, analysis, commentary)が関連付けられます。analysis チャンネルは思考連鎖(CoT)に使用され、final チャンネルはユーザへの最終回答に使用されます。
具体的には、以下の図のような入出力になります。
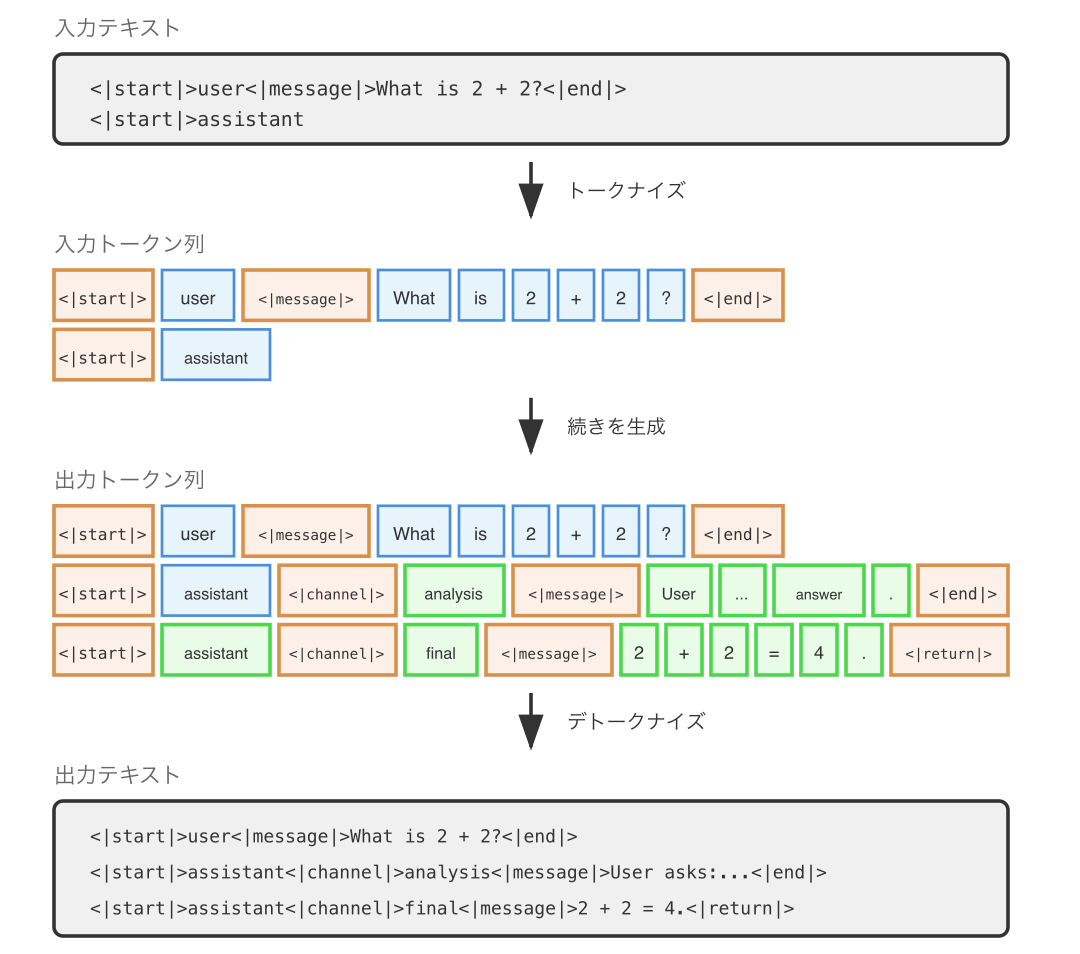
gpt-oss は DeepSeek-R1 の <think> / </think> とは異なるアプローチで深い思考を実現しています。DeepSeek-R1 が思考の開始と終了を明示するのに対し、gpt-oss はチャンネルによって思考と最終回答を分離していることが分かります。
GPT-5(OpenAI, 2025年8月) - パラメータ数非公開
2025年8月、OpenAI は GPT-5 をリリースしました(*24)。トークナイザはバイトレベル BPE 方式で、GPT-4o(2024年5月)や OpenAI o4-mini(2025年4月)で使用された o200k_base エンコーディングが使用されており、ボキャブラリサイズは約 200,000 です (*3)。
GPT-5 では Reasoning モデルの要素が Thinking モード という名前で目玉機能として追加されました(*24)。また、o シリーズと異なり、即時回答(Fast)モードと深い思考モード(Thinking)を自動で切り替える機能(Auto モード)が搭載されました。
技術的には、gpt-oss と同一か類似の特殊トークンを用いていると思われますが、詳細が公開されていないため具体的な特殊トークンは不明です。
GPT-5.1(OpenAI, 2025年11月) - パラメータ数非公開
GPT-5.1 では、思考トークンを全く使わない none モードが追加されました (*25)。Reasoning モデル特有の遅延を軽減するための仕組みです。
GPT-5.2(OpenAI, 2025年12月) - パラメータ数非公開
GPT-5.2 がリリースされたあたりで、ChatGPT で Thinking モードを利用している際の UI に 「Answer now(今すぐ回答する)」ボタン が追加されました (*26)。
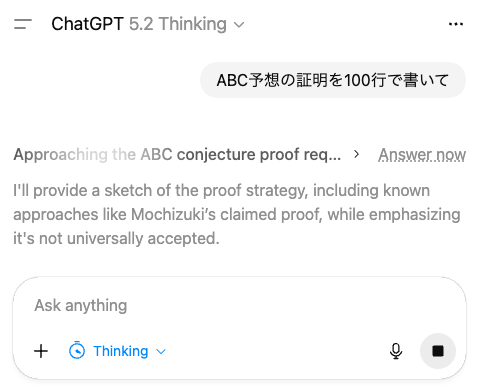
技術的詳細はやはり非公開ですが、仮に Harmony Response Format と同じ特殊トークンが用いられていると仮定すると、実装方法の想像は付きます。おそらく、「Answer now」ボタンを押すと <|end|> のような思考終了トークンが挿入されるのでしょう。そうすると、モデルはそれまでの思考結果を利用しつつ即座に思考をやめて回答を出すことができます。
さて、これで 2025 年 12 月現在までに導入された主な特殊トークンと、その活用方法の説明が完了しました!
ちなみに、まだまだ紹介しきれていない特殊トークンもあります。例えば、推論の過程で Python コードを実行する機能などは特殊トークンによって実現されています。興味のある方はぜひ調べてみてください。基本的にはモデルのトークナイザを調べれば特殊トークンの形式は分かります。
ところで、Reasoning モデルの次はどのような LLM が登場するのでしょうか?その答えも特殊トークンから迫っていくことができます。
今後の LLM と、特殊トークン
Reasoning モデルの次のパラダイムは何でしょうか?確実に言えるのは、次のパラダイムでも特殊トークンの追加が起こるということです。これまで見てきたように、特殊トークンは LLM が情報を受け取る方法や処理する方法を強力に制御する ものに他ならないからです。
また、その直感性を考えればしばらくは特殊トークンに頼るのが近道です。特殊トークンは、一見荒唐無稽な発想に対して、現実的な実装方法を与えることができるからです。
特殊トークンから考えれば、以下のようなモデルも比較的簡単に設計ができます。
リアルタイムチャットモデル
時刻トークンを導入すれば、ユーザの発言のテンポに応じた受け答えができるかもしれません。発話間隔をトークンで表現することで、相手が急いでいるのか、じっくり考えているのかをモデルが認識できるようになります。
音声トークンを入力として音声トークンを出力とするリアルタイムチャットモデルは既にありますが、時刻トークンと単語トークンの列に還元することで効率化が可能かもしれません。
感情認識チャットモデル
感情トークンを導入すれば、ユーザの感情を考慮した受け答えができるかもしれません。ユーザの感情状態をトークンで表現し、モデル側も応答のトーンをトークンで制御できるようになります。(ただし、EU 圏では感情認識 AI の利用に規制があるため注意が必要です。)
段階的思考モデル
思考レベルトークンを導入すれば、人間らしい段階的思考ができるかもしれません。一旦ユーザの発言に素早く応答し、その後じっくり考えて言葉を紡いでいくという流れです。即座の返答と深い考察を別々のトークンで制御するといった実装が考えられます。
エージェント間通信モデル
エージェント間通信トークンを導入すれば、エージェント同士の情報のやりとりを効率化することができるか��もしれません。現状は Reasoning モデルが出力したテキストを別エージェントに送ることによるエージェント間通信が多いですが、エージェント間通信は隠れ状態の共有による思考コミュニケーション (thought communication)(*27) が有効であることが知られていますし、記号推論 (symbolic reasoning) による推論圧縮 (reasoning compression)(*28) でエージェント間通信を効率化できる可能性もあります。
モデルのおさらい
この記事で出てきたモデルと、それらのモデルがどんな機能に対応していたかを表で整理してみましょう。
| モデル名 | 発表月 | 指示追従 | チャット | マルチモーダル | Reasoning |
|---|---|---|---|---|---|
| GPT-1 | 2018年6月 | ❌ | ❌ | ❌ | ❌ |
| BERT | 2018年10月 | ❌ | ❌ | ❌ | ❌ |
| GPT-2 | 2019年2月 | ❌ | ❌ | ❌ | ❌ |
| T5 | 2019年10月 | ✅ | ❌ | ❌ | ❌ |
| GPT-3 | 2020年5月 | ❌ | ❌ | ❌ | ❌ |
| InstructGPT | 2022年1月 | ✅ | ❌ | ❌ | ❌ |
| GPT-3.5 Turbo | 2022年11月 | ✅ | ✅ | ❌ | ❌ |
| GPT-4 | 2023年3月 | ✅ | ✅ | ✅ | ❌ |
| LLaVA | 2023年4月 | ✅ | ✅ | ✅ | ❌ |
| OpenAI o1 | 2024年9月 | ✅ | ✅ | ✅ | ✅ |
| DeepSeek-R1 | 2025年1月 | ✅ | ✅ | ❌ | ✅ |
| gpt-oss | 2025年8月 | ✅ | ✅ | ❌ | ✅ |
| GPT-5 | 2025年8月 | ✅ | ✅ | ✅ | ✅ |
| GPT-5.1 | 2025年11月 | ✅ | ✅ | ✅ | ✅ |
| GPT-5.2 | 2025年12月 | ✅ | ✅ | ✅ | ✅ |
おわりに
今回は LLM の特殊トークンについて、歴史的な変遷と各モデルの具体例を紹介しました。
GPT-1 の時代から考えると、特殊トークンの役割も随分と進化しましたよね。文の区切りを示すだけだったものが、今では「ここでユーザへの回答を始める」「ここで画像を読み込む」「ここで思考を始める」といった高度な制御に使われるようになっています。
ぜひ皆さんも新しい特殊トークンや入力形式を考えてみてください。それが次の LLM ブレイクスルーに繋がる可能性は十分にあります。
数ヶ月で状況が変わる AI 分野に対して、アシアルでは開発やデザイン、事務業務など、立場によらず AI を積極的に理解・活用する取り組みを行っています。興味のある方は会社情報や採用情報もご覧ください。
ではまた!
参考文献
(*1) Improving Language Understanding by Generative Pre-Training (GPT-1)
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
(*2) OpenAI GPT — transformers documentation
https://huggingface.co/transformers/v2.9.1/model_doc/gpt.html
(*3) openai/tiktoken - tiktoken/model.py
https://github.com/openai/tiktoken/blob/97e49cbadd500b5cc9dbb51a486f0b42e6701bee/tiktoken/model.py
(*4) openai/tiktoken: tiktoken is a fast BPE tokeniser for use with OpenAI's models.
https://github.com/openai/tiktoken
(*5) google/sentencepiece: Unsupervised text tokenizer for Neural Network-based text generation.
https://github.com/google/sentencepiece
(*6) Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
https://arxiv.org/abs/1910.10683
(*7) Large Language Models: A Survey
https://arxiv.org/abs/2402.06196v3
(*8) Aligning language models to follow instructions | OpenAI
https://openai.com/index/instruction-following/
(*9) openai-python/chatml.md at release-v0.28.0 · openai/openai-python
https://github.com/openai/openai-python/blob/release-v0.28.0/chatml.md
(*10) GPT-3.5 Turbo Model | OpenAI API
https://platform.openai.com/docs/models/gpt-3.5-turbo
(*11) Introducing APIs for GPT-3.5 Turbo and Whisper | OpenAI (Mar 1, 2023; Updated Apr 24, 2024)
https://openai.com/index/introducing-chatgpt-and-whisper-apis/
(*12) GPT-4 Technical Report
https://arxiv.org/abs/2303.08774
(*13) Visual Instruction Tuning (LLaVA)
https://arxiv.org/abs/2304.08485
(*14) o1 Preview Model | OpenAI API
https://platform.openai.com/docs/models/o1-preview
(*15) Reasoning models | OpenAI API
https://platform.openai.com/docs/guides/reasoning
(*16) Learning to reason with LLMs | OpenAI (Sep 12, 2024)
https://openai.com/index/learning-to-reason-with-llms/
(*17) OpenAI o1 System Card | OpenAI (Updated: Dec 5, 2024)
https://openai.com/index/openai-o1-system-card/
(*18) Reinforcement fine-tuning | OpenAI API
https://platform.openai.com/docs/guides/reinforcement-fine-tuning
(*19) DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
https://arxiv.org/abs/2501.12948
(*20) DeepSeek-R1 - tokenizer.json
https://huggingface.co/deepseek-ai/DeepSeek-R1/raw/56d4cbbb4d29f4355bab4b9a39ccb717a14ad5ad/tokenizer.json
(*21) DeepSeek-V3.2-Speciale - tokenizer.json
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Speciale/raw/c562883eda916fd699a44bbf1f4987a53b96008b/tokenizer.json
(*22) Introducing gpt-oss | OpenAI
https://openai.com/index/introducing-gpt-oss/
(*23) OpenAI Harmony Response Format | OpenAI Cookbook
https://cookbook.openai.com/articles/openai-harmony
(*24) Introducing GPT-5 | OpenAI
https://openai.com/index/introducing-gpt-5/
(*25) GPT-5.1 Prompting Guide | OpenAI Cookbook
https://cookbook.openai.com/examples/gpt-5/gpt-5-1_prompting_guide
(*26) GPT-5.2 in ChatGPT | OpenAI Help Center
https://help.openai.com/en/articles/11909943-gpt-52-in-chatgpt
(*27) Thought Communication in Multiagent Collaboration
https://arxiv.org/abs/2510.20733
(*28) ORION: Teaching Language Models to Reason Efficiently in the Language of Thought
https://arxiv.org/abs/2511.22891


























