図解で分かる!モダリティとマルチモーダルAI
エンジニアの又川(@n_matagawa)です。
今回は、GPT-4V や Gemini を初めとして2024年3月現在続々と登場しているマルチモーダルAIを感覚的かつ正確に理解するための考え方を紹介したいと思います。その根幹にあるモダリティという概念についても解説します。

マルチモーダルとは?
マルチモーダル(multimodal)とは、視覚・聴覚・言語などのモダリティ(modality)が複数使用されていることを意味する形容詞です。
モダリティという聞き慣れない単語が出てきましたが、この単語がとても重要なので詳しく解説していきます。
モダリティとは?
モダリティとは、辞書的には「何かが存在したり、経験されたりするための手段・方法・様式」という意味です(*1) (*2)。非常に抽象的なので具体例で理解していきま�しょう。
例えば、画像や映像は視覚的に存在し、視覚を通じて経験できるため、視覚モダリティ(visual modality)で説明されます。同様に、音声や音楽は聴覚モダリティ(auditory modality)で説明され、スマートフォンの振動は触覚モダリティ(tactile modality)で説明されます。このように、五感のそれぞれは基本的にモダリティに含まれます。
しかしここで重要なのは、モダリティは五感に限られないということです。例えば、文章は画像や音声、振動と違って抽象的な存在です。文章はインクの染みとして視覚的に存在することもあれば、音声や点字として聴覚的・触覚的な形で存在することもあります。しかし、文章は最終的には脳内に言語情報として存在し、言語を通じて経験されるため、言語モダリティ(language modality, linguistic modality, text modality)で説明されます。
その他のモダリティについては英語版 Wikipedia の Modality (human–computer interaction) の記事によくまとまっているので、より詳しく知りたい方はそちらを参照してください。
改めて、マルチモーダルとは?そしてマルチモーダルAIとは?
マルチモーダル(multimodal)とは、視覚・聴覚・言語などのモダリティ(modality)が複数使用されていることを意味する形容詞です。
ですが、マルチモーダルAI(multimodal AI)と言った場合は入力が複数のモダリティで構成されているAIモデルのことを指します(*3)。出力は考慮されません。
ユニモーダルとユニモーダルAI
逆に、モダリティが1つしか使用されていないことをユニモーダル(unimodal)と言います。分かりやすさを考慮してかシングルモーダル(single-modal)という表現も最近よく見かけますが、歴史的にはあまり一般的ではありません(*4)。
マルチモーダルAIの時と同様に、ユニモーダルAI(unimodal AI)と言った場合は入力が1つのモダリティで構成されているAIモデルのことを指し、出力は考慮されません。
図で考えるマルチモーダルAI
ここまでの話を元に図を考えてみましょう。以下は、人間やAIモデルの入力と出力を可視化したものです。人間が直接知覚できるモダリティは青色で示し、人間が直接知覚できないモダリティは赤色で示しました。
人間は五感を初めとしたマルチモーダルな入力を処理できるため、定義に無理やり当てはめるとマルチモーダルAIに相当します。出力は色々な考え方ができますが、基本的には運動ができて発話ができるので触覚モダリティと聴覚モダリティがメインの出力と言えるでしょう。機械のように映像を表示したりすることはできないので視覚モダリティの出力には弱く、味や匂いを他人に伝えることは全くできないので味覚モダリティと嗅覚モダリティの出力はできないと言えます。
GPT-4V は画像(視覚モダリティ)と質問文(言語モダリティ)を同時に入力することができるため、マルチモーダルAIに相当します。
図で考えるユニモーダルAI
ユニモーダルAIの入力と出力についても可視化してみましょう。以下はよくあるユニモーダルAIです。
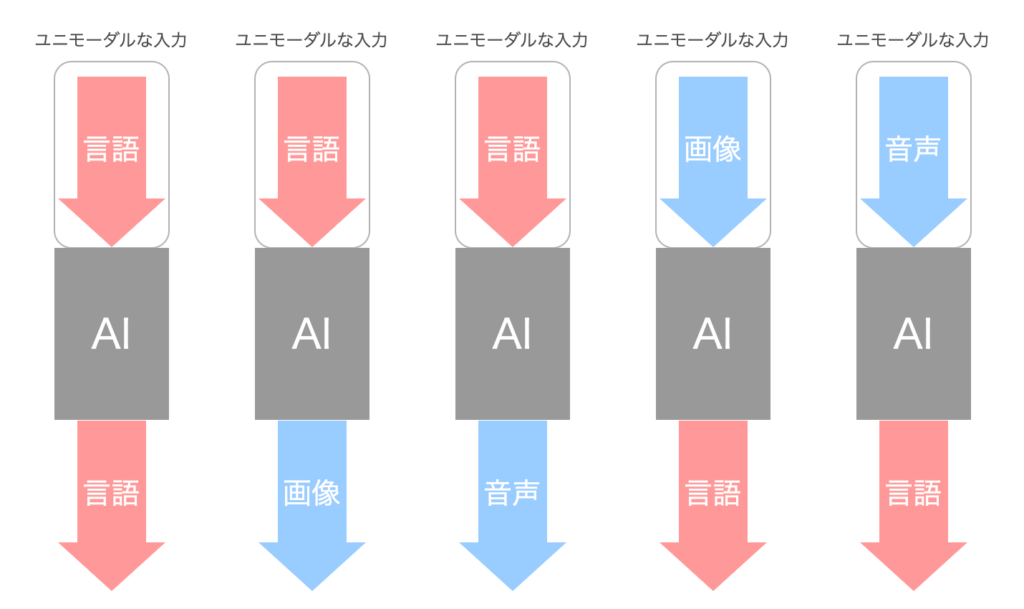
言語を入力として言語を出力するAI(Text-to-Text)や、言語を入力として画像(視覚モダリティ)を出力するAI(Text-to-Image)、言語を入力として音声(聴覚モダリティ)を出力するAI(Text-to-Audio)、逆に画像を入力として言語を出力するAI(Image-to-Text)、音声を入力として言語を出力するAI(Audio-to-Text)、これらは全てユニモーダルAIです。
微妙な存在たち
2024年3月現在、各組織から様々なAIシステムが発表されています。しかしその中には、「これはマルチモーダルAIなのか?」と悩んでしまうようなAIシステムが少なからず存在します。典型的な例を2つ紹介します。
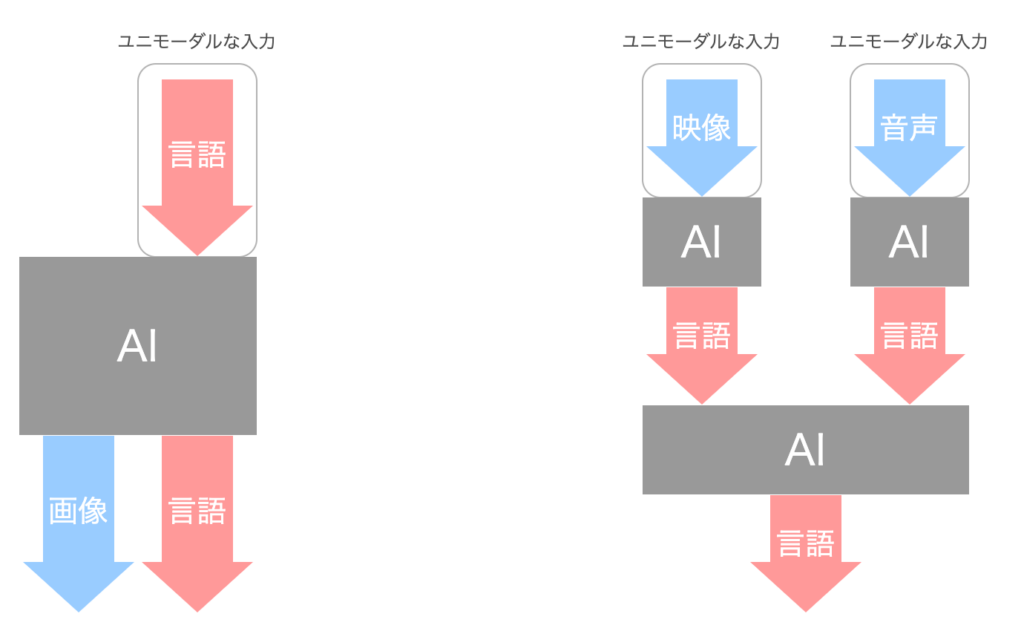
1つ目は、出力だけが複数のモダリティを持つようなAIシステムです。例えば、文字列を入力すると画像に説明文を添えて出力してくれるようなAIシステムがこの場合に相当します。このようなAIシステムは、全体としては2つ以上のモダリティが関わっていますが、入力モダリティが1種類であるため定義上はユニモーダルAIです。
2つ目は、ユニモーダルAIの組み合わせで複数のモダリティが処理されているようなAIシステムです。例えば、音声付きの映像を入力すると内容を文章で説明してくれるものの、内部的には2つのユニモーダルAI(Video-to-Text と Audio-to-Text)の出力結果を使って文章を生成しているようなAIシステムがこの場合に相当します。全体として見れば入力モダリティが複数ありますが、使われているAIモデルが1つではないためマルチモーダルAIには相当しません。あくまでユニモーダルAIの組み合わせで作られたAIシステムと言えます。
マルチモーダルAIの条件: クロスモーダルな処理
ではどんなものがマルチモーダルAIと言えるのかというと、一般的には内部で異なるモダリティの情報を統合するクロスモーダル(cross-modal)な処理が組み込まれているAIモデルがマルチモーダルAIと言えます。
Gemini の場合、テキスト・画像・音声・動画の情報を細切れにし、1本の入力シーケンス(interleaved sequence)にすることでクロスモーダルな処理を実現しています(*5)。
他にもクロスモーダルな処理を実現する方法としては cross-modal self-attention(*6) や multimodal Transformer(*7) など、cross-modal 〇〇 や multimodal 〇〇 という名前の仕組みが大量に存在します。
おわりに
今回はマルチモーダルAIを感覚的かつ正確に理解するための考え方を紹介しました。
2024 年はAIモデルの「軽量化」「入力のマルチモーダル化」「出力のマルチモーダル化」「リアルタイム化」「自律化」がさらに進んでいく年であろうと予想しています。機会があればリアルタイム化や自律化に関する記事も投稿したいと思います。
ではまた!
脚注
(*1) Oxford Advanced Learner's Dictionary では「the particular way in which something exists, is experienced or is done」(何かが存在する、経験される、または行われる際の特定の方法)と説明されています。
(*2) 言語学・医学・生理学における「モダリティ」はまた違った定義を持っています。この記事では HCI(ヒューマンコンピュータインタラクション)における「モダリティ」の意味を説明しています。
(*3) Google の記事では「A multimodal model is a ML (machine learning) model that is capable of processing information from different modalities, including images, videos, and text.」、Meta の記事では「Multimodal generative AI systems typically rely on models that combine types of inputs, such as images, videos, audio, and words provided as a prompt.」と説明されています。Hugging Face では「Image-Text-to-Text」タスク・「Visual Question Answering」タスク・「Document Question Answering」タスクのような複数のモダリティを入力とするタスクのみが「Multimodal」カテゴリに収められています。
(*4) Google Trends で「multimodal, unimodal, single-modal, singlemodal, single modal」の検索ボリュームを比較したり、「マルチモーダル, ユニモーダル, シングルモーダル」の検索ボリュームを比較したりすると明らかです。
(*5) Gemini の論文の Figure 2 に「Gemini supports interleaved sequences of text, image, audio, and video as inputs」とあります。
(*6) Cross-Modal Self-Attention Network for Referring Image Segmentation (CVPR 2019)。
(*7) Multimodal Learning with Transformers: A Survey (2022)。multimodal Transformer 等に関するサーベイ論文です。